[Python/Crawling] 네이버 로그인(캡챠 해결)
네이버 로그인 크롤러를 만들어보자.
한번 만들어 놓으면 네이버 로그인이 필요한 사이트를 크롤링 할 때 유용하게 쓸 수 있다.
먼저 크롬 드라이버를 설치되어 있어야한다. 설치되어 있지 않다면 다음과 같은 방법으로 설치해보자.
▷ 크롬 드라이버 설치
1. 내 크롬 버전 확인
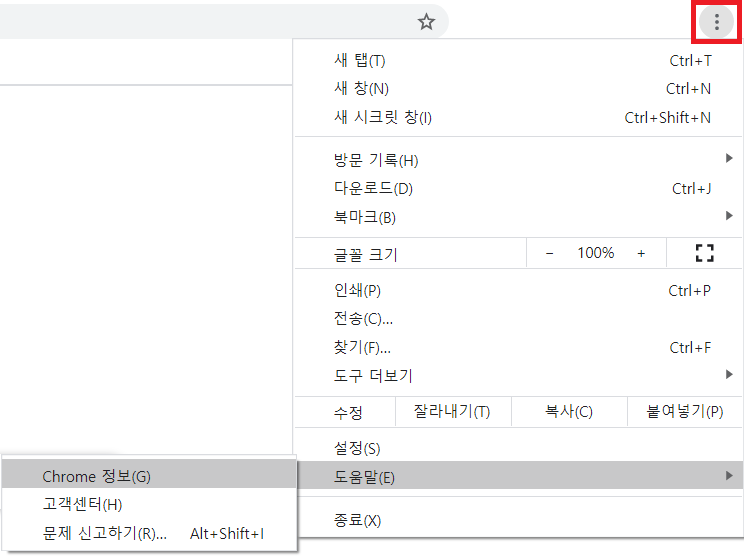
크롬의 버전을 먼저 확인해야 한다. 오른쪽 위에 설정버튼을 누르면 버전을 확인할 수 있다.
2. 크롬 버전에 맞는 드라이버 다운로드
확인한 크롬 버전에 맞는 드라이버를 다운해주면 된다.
https://chromedriver.chromium.org/downloads
3. 압축 풀고 원하는 경로로 chromedriver.exe를 이동
크롤링을 할 때 웹 브라우저의 경로를 입력해야하기 때문에 기억하도록 하자.
▷ 네이버 로그인 코드
□ 라이브러리 호출
import time
import pyperclip
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
□ 네이버 로그인 페이지 접속
설치한 크롬 드라이버를 통해서 네이버 로그인 페이지에 접속한다. 주석 처리된 headless 옵션을 넣어주면 브라우저가 화면 상에 보이지 않는다. 예시를 보여주기 위해 주석처리 해놓았지만 실제 데이터를 크롤링 할 땐 옵션을 넣는 것을 추천한다.
# 크롬 웹 드라이버의 경로를 설정
driverLoc = # 크롬 드라이버 경로 입력
options = webdriver.ChromeOptions()
# options.add_argument("--headless") # 브라우저 숨기기
driver = webdriver.Chrome(driverLoc, chrome_options=options)
# 네이버 로그인 페이지 접속
driver.get("https://nid.naver.com/nidlogin.login")
□ 네이버 id, pw 입력
# 로그인 정보
login = {"id" : "" # 네이버 아이디
,"pw" : "" # 네이버 비밀번호
}
# 로그인 정보 입력 함수
def clipboard_input(user_xpath, user_input):
temp_user_input = pyperclip.paste()
pyperclip.copy(user_input)
driver.find_element_by_xpath(user_xpath).click()
ActionChains(driver).key_down(Keys.CONTROL).send_keys('v').key_up(Keys.CONTROL).perform()
pyperclip.copy(temp_user_input)
time.sleep(1)
□ 네이버 로그인 버튼 클릭
xpath를 이용하여 네이버 로그인 버튼을 클릭한다.
xpath 확인 방법 클릭!
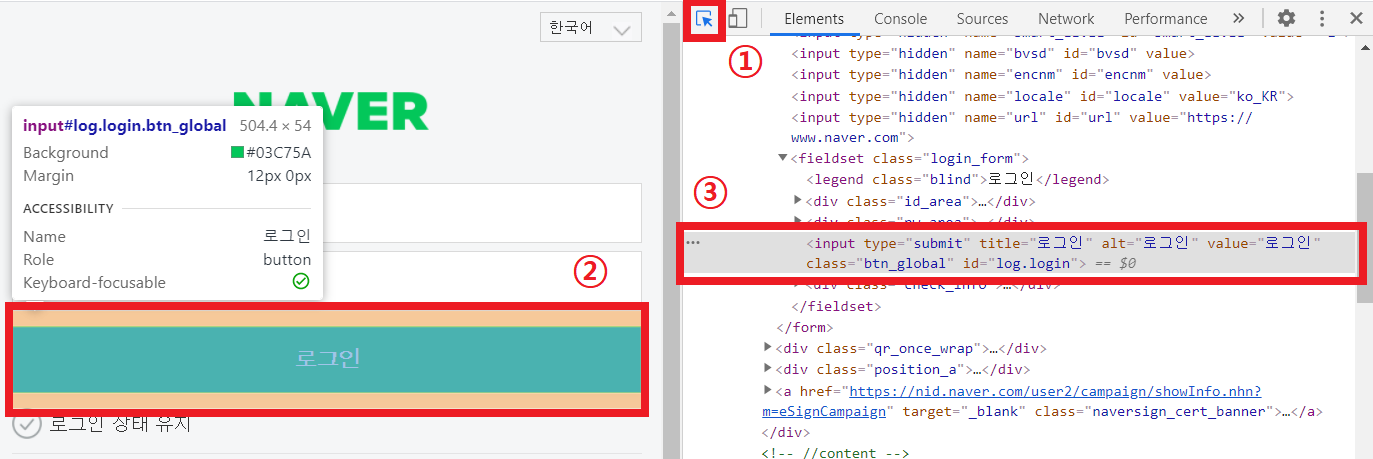
크롬에서 F12를 누르면 다음과 같은 화면을 볼 수 있다.
-
페이지 구성요소를 확인할 수 있는 도구를 선택한다.
-
클릭하고 싶은 요소을 누른다.
-
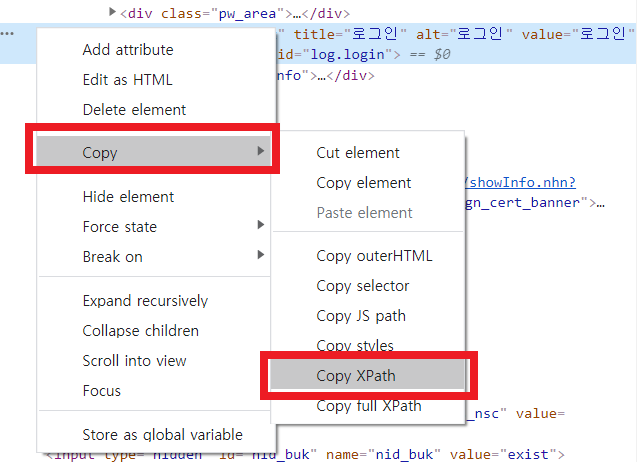
클릭하고 싶은 요소에 대한 html에서 마우스 우클릭해서 다음과 같이 xpath를 복사할 수 있다.
# id, pw 입력 후 클릭
clipboard_input('//*[@id="id"]', login.get("id"))
clipboard_input('//*[@id="pw"]', login.get("pw"))
driver.find_element_by_xpath('//*[@id="log.login"]').click()
time.sleep(10)
Leave a comment