[논문리뷰] Item-based Collaborative Filtering Recommendation Algorithms
Abstract
정보의 양과 웹사이트 방문자 수가 엄청나게 증가함에 따라 추천 시스템에 추가적인 문제가 생겼다. : 고품질 추천 생성, 수백만명 사용자에 대한 실시간 추천, 데이터 희소성. 기존의 협업 필터링 시스템의 작업량은 시스템 이용자 수에 따라 증가한다. 큰 규모의 문제에서도 고품질 추천을 신속하게 생성할 수 있는 새로운 추천 시스템 기술이 필요하다. 문제를 해결하기 위해 항목 기반 협업 필터링을 살펴본다. 항목 기반 기술은 사용자 항목 매트릭스를 분석하여 서로 다른 항목 간의 관계를 식별한 다음 관계를 사용하여 사용자에 대한 추천 사항을 간접적으로 계산한다.
이 논문에서는 다양한 항목 기반 추천 생성 알고리즘을 분석한다. item-item 유사성을 계산하기 위한 다양한 기술(ex. item-item 상관 vs. item 벡터 간의 코사인 유사도)과 추천 사항을 얻기 위한 다양한 기술(ex. weighted sum vs. regression model)을 조사한다. 마지막으로 결과를 실험을 통해 평가하고 기본 k-최근접 이웃 접근법과 비교한다. 실험 결과는 항목-기반(item-based) 알고리즘이 사용자-기반(user-based) 알고리즘보다 더 좋은 성능을 제공했다.
1 Introduction
협업 필터링(collaborative filtering) 은 사용자 당 항목에 대한 선호도 데이터베이스를 구축하여 사용한다. 예를 들어 새로운 사용자인 Neo를 데이터베이스에서 Neo와 비슷한 취향을 가진 다른 사용자를 찾는다. 주변 사람들이 좋아하는 항목은 Neo에게 추천된다. 협업 필터링은 연구와 실험, 정보 필터링 앱과 E-커머스 앱에서 모두 성공적이었지만, 두가지 문제가 있다.
첫번째는 확장성을 향상시키는 것이다. 이러한 알고리즘은 수만개의 잠재적인 이웃을 실시간으로 검색할 수 있지만, 추천 시스템은 수천만개의 잠재적인 이웃을 검색해야한다. 또한 기존 알고리즘은 사이트에 많은 정보가 있는 개별 사용자에게 성능 문제가 있다. 예를 들어 사이트에서 검색 패턴을 콘텐츠 선호도의 지표로 사용하는 경우 가장 빈번한 방문자에 대한 수천개의 데이터 포인트가 있을 수 있다. 이러한 “긴 사용자 행”은 초 당 검색할 수 있는 인접 항목수를 줄여 확장성을 감소시킨다.
두번째는 사용자를 위한 추천 항목의 품질을 개선하는 것이다. 사용자는 좋아할 항목을 찾는데 도움이 되도록 신뢰할 수 있는 추천 사항이 필요하다. 사용자는 자신에게 일관되게 정확하지 않은 추천 시스템을 사용하는 것을 거부함으로써 “발로 투표”한다.
알고리즘이 이웃을 검색하는데 소요되는 시간이 적을수록 확장성이 높아지고 품질이 저하되기 때문에 이 두 가지 문제가 충돌한다. 이러한 이유로 발견된 솔루션이 유용하고 실용적이도록 두가지 문제를 동시에 처리하는 것이 중요하다.
본 논문에서는 항목 기반 알고리즘을 적용하여 추천 시스템의 이러한 문제를 해결한다. 기존의 협업 필터링 알고리즘의 병목 현상은 잠재적인 이웃의 대규모 사용자 집단 중에서 이웃을 검색하는 것이다. 항목 기반 알고리즘은 사용자 간의 관계가 아닌 항목 간의 관계를 먼저 탐색하여 이러한 병목 현상을 방지한다. 사용자에 대한 추천은 사용자가 좋아한 다른 항목과 유사한 항목을 찾아 계산된다. 항목 간의 관계가 상대적으로 정적이기 때문에 항목 기반 알고리즘은 적은 계산으로 사용자 기반 알고리즘과 동일한 품질을 제공할 수 있다.
1.2 Contributions
이 연구는 세가지 부분에서 의미를 가진다.
- 항목 기반 예측 알고리즘의 분석과 하위 작업을 구현하는 다양한 방법을 보여준다.
- 항목 기반 권장 사항의 온라인 확장성을 높이기 위해 항목 유사성의 사전 계산된 모델을 공식화한다.
- 기존의 사용자 기반(최근접 이웃) 알고리즘과 여러 가지 항목 기반 알고리즘의 성능을 비교한다.
1.3 Organization
논문은 다음과 같이 구성됩니다. 다음 장에서는 협업 필터링 알고리즘에 대한 간략한 배경 지식을 제공한다. 먼저 협업 필터링 프로세스를 공식적으로 설명한 다음 두 가지 변형 메모리 기반과 모델 기반 접근 방식에 대해 논의한다. 그런 다음 메모리 기반 접근 방식과 관련된 몇가지 문제를 제시한다. 3장에서는 항목 기반 접근 방식을 제시하고 알고리즘의 여러 하위 작업을 자세히 설명한다. 4장은 성능 실험을 설명한다. 데이터 세트, 평가 지표, 방법론, 다양한 실험 결과를 보여준다. 마지막 장에서는 향후 연구를 위한 결론과 방향을 제시한다.
2 Collaborative Filtering Based Recommender Systems
추천 시스템은 좋음 가능성 점수나 지정된 사용자에 대한 상위 N개 추천 항목 목록을 생성하여 E-커머스에서 구매하려는 항목을 찾을 수 있도록 돕는다. 항목 추천은 다른 방법을 사용하여 만들 수 있다. 사용자의 인구 통계, 전체적으로 가장 많이 팔리는 항목, 사용자의 과거 구매 습관을 예측 변수로 사용할 수 있다. CF(Collaborative Filtering)는 현재까지 가장 성공적인 추천 기법이다. CF 기반 알고리즘의 기본 아이디어는 같은 취향을 가진 다른 사용자의 의견을 기반으로 항목 추천이나 예측을 제공한다. 사용자의 의견은 사용자로부터 명시적으로나 일부 암시적 조치를 사용하여 얻을 수 있다.
2.0.1 Overview of the Collaborative Filtering Process
협업 필터링 알고리즘은 사용자가 이전에 좋아하는 것과 같은 취향을 가진 다른 사용자의 의견을 기반으로 새 항목을 제안하거나 특정 사용자에게 특정 항목의 유용성을 예측한다. 일반적인 CF 시나리오는 m명의 사용자 목록 및 n개의 항목 목록
이 있다. 각 사용자
에는 사용자가 자신의 의견을 표현한 항목 목록
이 있다. 의견은 일반적으로 특정 수치 척도 내에서 평점 점수로 사용자에 의해 명시적으로 제공되거나, 타이밍 로그 분석, 웹 하이퍼 링크 마이닝 등을 통해 구매 기록에서 암시적으로 도출될 수 있다.
나
될 수 있다. 두 가지 형태의 항목 유사성을 찾는 것이 협업 필터링 알고리즘의 임무인 활성 사용자라고 하는 고유 사용자
가 있다.
-
예측은 활성 사용자
에 대한 항목
의 예측 가능성을 나타내는 값
다. 이 예측값
-
추천은 활성 사용자가 가장 좋아할 N개 항목
이다. 추천 항목은 활성 사용자가 아직 구매하지 않은 항목(ex.
)이어야 한다. 이 CF 알고리즘 인터페이스는 Top-N Recommendation이라고도 한다.
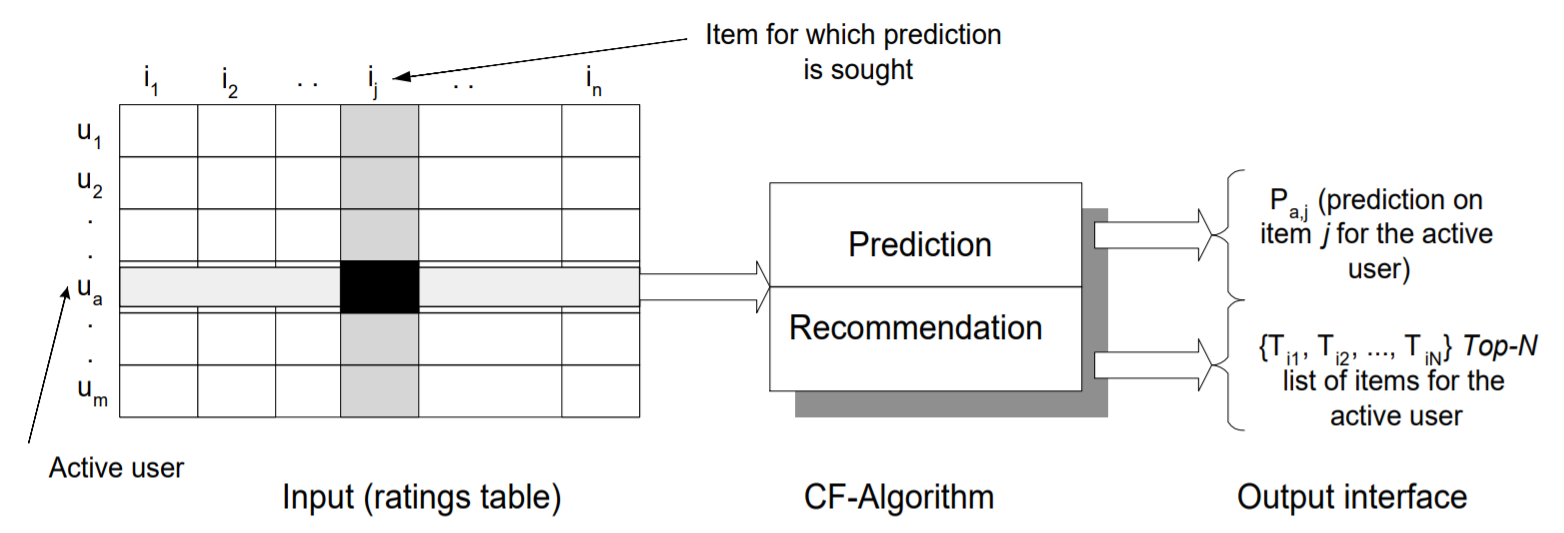
위 그림은 협업 필터링 프로세스를 보여준다. CF 알고리즘은 전체 m×n 사용자 항목 데이터를 등급 행렬 로 나타낸다. 행렬의 각 항목
는 j번째 항목에서 i번째 사용자의 선호도 점수(등급)를 나타낸다. 각 개별 등급은 숫자 척도 내에 있으며 사용자가 아직 해당 항목을 평가하지 않았음을 나타내는 0일 수도 있다. 여러 협업 필터링을 두가지 주요 범주로 니늘 수 있다.-메모리 기반(사용자 기반) 과 모델 기반(항목 기반) 알고리즘. 이번 장에서는 CF 기반 추천 시스템 알고리즘을 자세히 설명한다.
Memory-based Collaborative Filtering Algorithms
메모리 기반 알고리즘은 전체 사용자 항목 데이터베이스를 활용하여 예측한다. 통계적 기법을 사용하여 대상 사용자와 동의한 기록이 있는 이웃(서로 다른 항목을 비슷하게 평가하거나 비슷한 항목 집합을 구입하는 경향이 있음)이라고하는 사용자 집합을 찾는다. 사용자의 이웃이 형성되면 이러한 시스템은 서로 다른 알고리즘을 사용하여 이웃의 선호도를 결합하여 활성 사용자에 대한 예측이나 top-N 추천 목록을 생성한다. 최근접 이웃이나 사용자 기반 협업 필터링이라고 하는 이 기술은 더 널리 사용된다.
Model-based Collaborative Filtering Algorithms
모델 기반 협업 필터링 알고리즘은 먼저 사용자 평가 모델을 개발하여 항목 추천을 제공한다. 이 범주의 알고리즘은 확률적 접근 방식을 취하고 다른 항목에 대한 평가를 고려하여 사용자 예측의 예상 값을 계산하는 협업 필터링 프로세스를 구상한다. 모델 구축 프로세스는 베이지안 네트워크, 클러스터링, 규칙 기반 방식과 같은 다양한 기계 학습 알고리즘을 사용한다. 베이지안 네트워크 모델은 협업 필터링 문제에 대한 확률 모델을 공식화한다. 클러스터링 모델은 협업 필터링을 분류 문제로 취급하고 같은 클래스의 유사한 사용자를 클러스터링하고 특정 사용자가 특정 클래스 C에 속할 확률을 추정하는 방식으로 작동하며 여기에서 등급의 조건부 확률을 계산한다. 규칙 기반 접근 방식은 연관 규칙 발견 알고리즘을 적용하여 공동 구매 품목 간의 연관성을 찾은 다음 품목 간의 연관 강도에 따라 품목 추천을 생성한다.
2.0.2 Challenges of User-based Collaborative Filtering Algorithms
사용자 기반 협업 필터링 시스템은 성공적이었지만, 널리 사용되면서 다음과 같은 몇 가지 잠재적인 문제가 나타났다.:
- 희소성(Sparsity) 실제 상업적 추천 시스템은 큰 아이템 세트를 평가하는데 사용된다(Amazon.com은 책을 추천하고 CDnow.com은 음악 앨범을 추천함). 이러한 시스템에서는 활성 사용자도 항목의 1% 미만을 구매했을 수 있다(2백만권의 1%는 2만권). 따라서 최근접 알고리즘에 기반한 추천 시스템은 특정 사용자에 대한 어떠한 항목 추천도하지 못할 수 있다. 결과적으로 추천 사항의 정확성이 떨어질 수 있다.
- 확장성(Scalability) 최근접 이웃 알고리즘은 사용자 수와 항목 수에 따라 더 많은 계산이 필요하다. 수백만 명의 사용자와 항목이 있는 기존 알고리즘을 실행하는 일반적인 웹 기반 추천 시스템은 심각한 확장성 문제를 겪게 된다.
최근접 이웃 알고리즘은 대규모 희소(sparse) 데이터베이스에 적용하기 어렵기 때문에 다른 방법을 고려했다. 첫번째 접근 방식은 반-지능적인(semi-intelligent) 필터링 에이전트를 시스템에 통합하여 희소성을 연결한다. 이러한 에이전트는 syntactic 피처들을 사용하여 각 항목을 평가한다. 밀도가 높은 등급 세트를 제공함으로써 적용 범위를 줄이고 품질을 개선하는데 도움이 되었다. 그러나 필터링 에이전트 솔루션은 같은 취향을 가지고 있지만 드문 사용자 간 관계가 별로 없다는 근본적인 문제를 해결하지 못한다. 알고리즘 접근 방식을 취하고 LSI(Latent Semantic Indexing)를 사용하여 축소된 차원 공간에서 사용자와 항목 간의 유사성을 포착했다. 확장성(scalability) 문제를 해결하기위해 모델 기반 접근 방식을 살펴본다. 주요 아이디어는 사용자 항목 표현 행렬을 분석하여 서로 다른 항목 간의 관계를 식별한 다음 이러한 관계를 사용하여 주어진 사용자 항목 쌍에 대한 예측 점수를 계산한다. 이 방법의 가정은 사용자가 이전에 좋아했던 항목과 유사한 항목을 재구매하고, 사용자가 이전에 좋아하지 않았던 항목은 피하는 경향이 있다는 것이다. 이 기술은 추천이 요청될 때 유사한 사용자를 식별할 필요가 없기 때문에 빠르게 추천 결과를 낸다. 확률론적 접근부터 전통적인 item-item correlation에 이르는 항목 간의 연관성을 계산하기 위한 다양한 방법이 제안되었다. 다음 장에서 접근 방식에 대한 자세한 분석을 제시한다.
3. Item-based Collaborative Filtering Algorithm
이 장에서는 사용자에게 예측을 생성하기 위한 항목 기반 추천 알고리즘 클래스를 연구한다. 2장에서 논의된 사용자 기반 협업 필터링 알고리즘과 달리 항목 기반 접근 방식은 대상 사용자가 평가한 항목 집합을 조사하고 대상 항목 i와 얼마나 유사한지 계산한 다음 가장 유사한 항목 k개를 선택하고, 동시에 해당 유사성
를 계산한다. 가장 유사한 항목이 발견되면 이러한 유사한 항목에 대한 대상 사용자 평가의 가중 평균을 취하여 예측을 계산한다. 두가지 측면, 즉 유사성 계산과 예측 생성에 대해 자세히 설명한다.
3.1 Item Similarity Computation
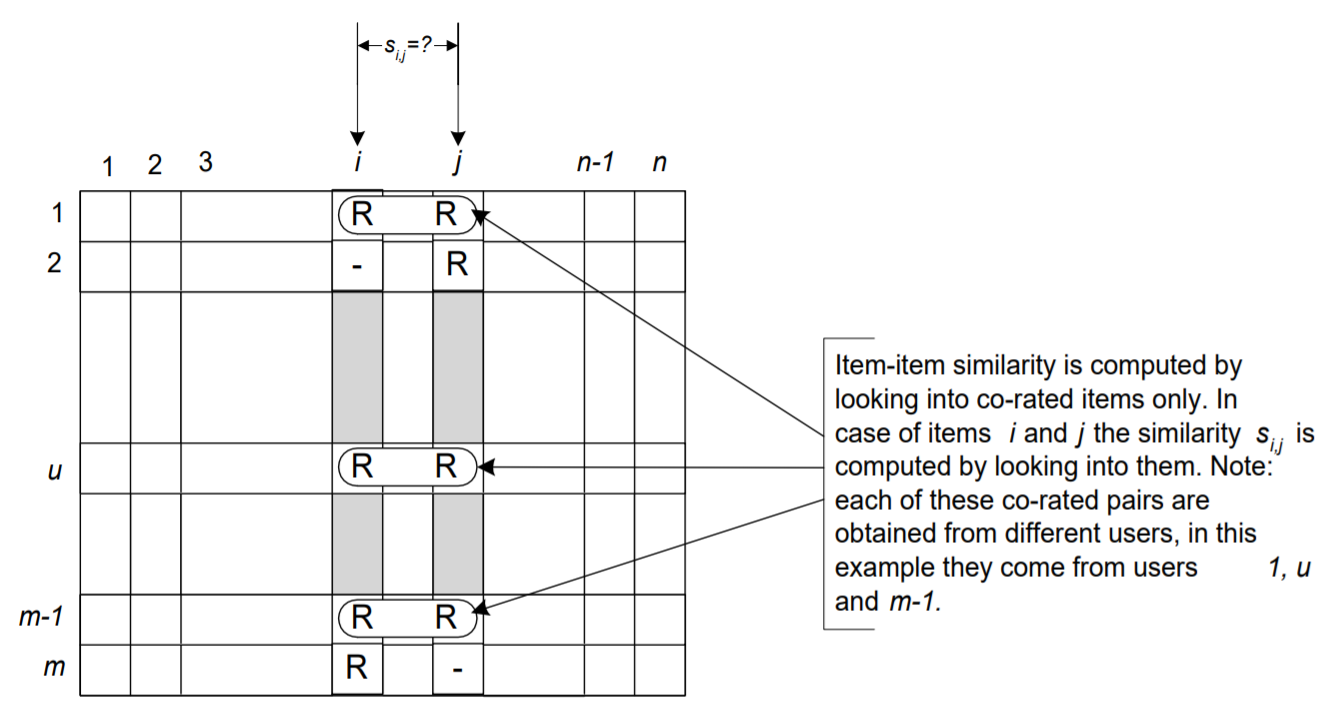
항목 기반 협업 필터링 알고리즘의 중요한 단계 중 하나는 항목 간의 유사성을 계산한 다음 가장 유사한 항목을 선택한다. 두 항목 i와 j의 유사성 계산의 기본 아이디어는 먼저 이러한 항목을 모두 평가한 사용자를 분리한 다음 유사성을 계산하여 유사성 를 결정한다. 위 그림은 이 프로세스를 보여준다. 여기서 행렬 행은 사용자를 나타내고 열은 항목을 나타낸다.
항목 간의 유사성을 계산하는 세가지 소개한다.: 코사인 기반 유사성, 상관 기반 유사성, 수정된 코사인 유사성
3.1.1 Cosine-based Similarity
이 경우 두 항목은 m차원 사용자 공간에서 두개의 벡터로 간주된다. 이들 사이의 유사성은이 두 벡터 사이 각도의 코사인을 계산한다. 공식적으로 m×n 등급 행렬에서 sim(i, j)로 표시된 항목 i와 j 사이의 유사성은 다음과 같다.
3.1.2 Correlation-based Similarity
이 경우 두 항목 i와 j 사이의 유사성은 Pearson-r correlation 를 계산한다.
상관관계를 정확하게 계산하기위해 공동 평가된 케이스(사용자가 i와 j를 모두 평가한 케이스)를 분리해야한다. i와 j를 모두 평가하고 사용자 집합을 U로 표시한 다음 상관 유사성은 다음과 같이 주어진다.
3.1.3 Adjusted Cosine Similarity
사용자 기반 CF의 경우 유사성이 행렬의 행을 따라 계산되지만, 항목 기반 CF의 경우 유사성이 함께 계산된다. 즉 공동 등급 세트의 각 쌍은 다른 사용자에 해당한다. 항목 기반 사례에서 기본 코사인 측정값을 사용하여 유사성을 계산하면 한가지 중요한 단점이 있다. 다른 사용자 간의 평가 척도 차이는 고려되지 않는다. 수정된 코사인 유사성은 다음을 빼서 이 단점을 상쇄한다.
3.2 Prediction Computation
협업 필터링 시스템에서 가장 중요한 단계는 예측 측면에서 출력 인터페이스를 생성하는 것이다. 유사성 측정값을 기반으로 가장 유사한 항목 집합을 분리한 후, 대상 사용자 등급을 조사하고 기술을 사용하여 예측한다. 여기서 두가지 방법을 고려한다.
3.2.1 Weighted Sum
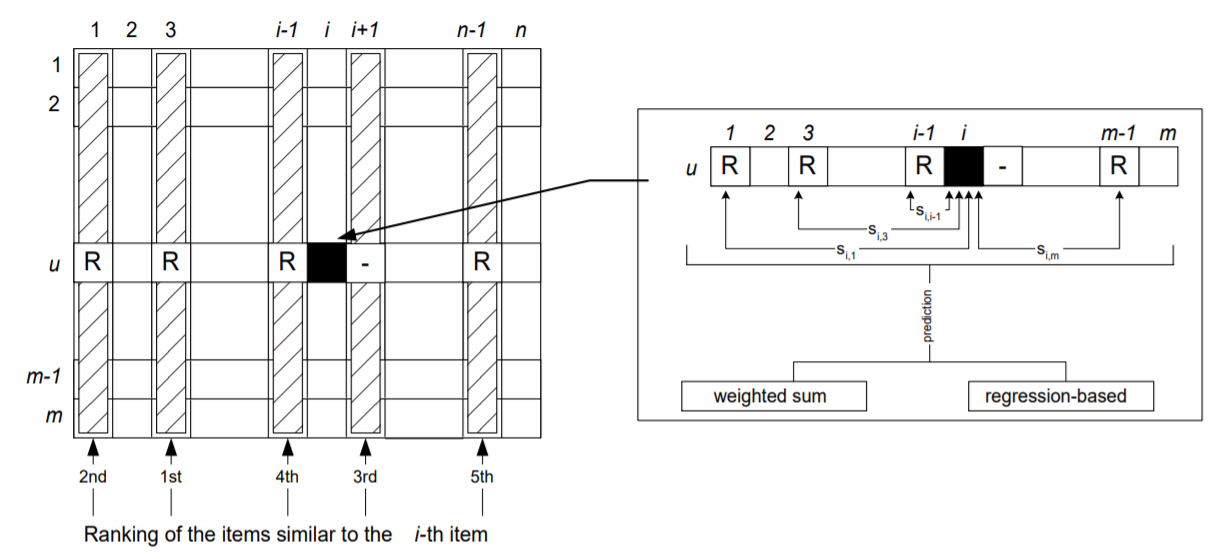
i와 유사한 항목에 대해 사용자가 부여한 평점의 합계를 계산하여 사용자 u에 대한 항목 i에 대한 예측을 계산한다. 각 등급은 항목 i와 j 사이의 유사성 에 의해 가중치를 부여한다. 공식적으로 위 그림에 표시된 개념을 사용하여 예측을 다음과 같이 나타낼 수 있다.
기본적으로 이 접근 방식은 활성 사용자가 유사한 항목을 평가하는 방법을 포착한다. 가중 합계는 예측이 사전 정의된 범위 내에 있는지 확인하기 위해 유사성 항의 합한다.
3.2.2 Regression
가중 합계 방법과 유사하지만 유사한 항목의 등급을 직접 사용하는 대신 회귀 모델을 기반으로 한 등급의 근사치를 사용한다. 코사인과 상관 측정을 사용하여 계산된 유사성은 두 등급 벡터가 멀리 떨어져있을 수 있지만(유클리드 관점에서) 매우 높은 유사성을 가질 수 있다는 점에서 오해의 소지가 있을 수 있다. 이 경우 “소위” 유사한 항목의 원시 등급을 사용하면 예측이 좋지 않을 수 있다. 기본 아이디어는 가중 합계 기법과 동일한 공식을 사용하는 것이지만 유사한 항목 N의 “원시(raw)” 등급값
을 사용하는 대신이 모델은 선형 회귀를 기반으로 한 근사값
을 사용한다. 목표 항목 i와 유사한 항목 N의 각 벡터를
및
으로 표시하면 선형 회귀 모델을 다음과 같이 표현할 수 있다.
회귀 모델 매개 변수 α 및 β는 두 등급 벡터를 모두 검토하여 결정된다. 은 회귀 모델에서 오류를 나타낸다.
3.3 Performance Implications
가장 큰 E-커머스 사이트는 협업 필터링의 직접적인 구현을 강조하는 규모로 운영된다. 이웃 기반 CF 시스템에서 이웃 형성 프로세스, 특히 사용자-사용자 유사성 계산 단계는 성능 병목 현상이 있어서 전체 프로세스가 실시간 추천 생성에 적합하지 않다. 높은 확장성을 보장하는 한가지 방법은 모델 기반 접근 방식을 사용하는 것이다. 모델 기반 시스템은 추천 시스템이 대규모로 작동하는데 기여할 수 있다. 여기서 주요 아이디어는 이웃 생성과 예측 생성 단계를 분리하는 것이다.
항목-항목 유사성 점수를 미리 계산하기 위해 모델 기반 접근 방식을 제시한다. 유사성 계산 체계는 여전히 상관관계 기반이지만 계산은 항목 공간에서 수행된다. E-커머스 시나리오는 가장 자주 변경되는 사용자 수에 비해 정적인 항목 집합이 있다. 항목의 정적 특성은 항목 유사성을 미리 계산하는 아이디어로 이어진다. 항목 유사성을 미리 계산하는 한가지 가능한 방법은 전체 유사성을 계산한 다음 빠른 테이블 조회를 수행하여 필요한 유사성 값을 검색한다. 이 방법은 시간을 절약하지만 n개 항목에 대해 공간이 필요하다.
예측을 계산하기 위해 유사한 항목의 작은 부분만 필요하다는 사실은 우리를 대체 모델 기반 체계로 이끈다. 이 계획에서는 적은 수의 유사한 항목만 유지한다. 각 항목 j에 대해 가장 유사한 k 개의 항목을 계산합니다. 여기서 k«n은 이러한 항목 번호와 그 유사성을 j로 기록한다. k는 모델 크기다. 이 모델 구축 단계를 기반으로 우리의 예측 생성 알고리즘은 다음과 같이 작동한다. 항목 i에 대한 사용자 u에 대한 예측을 생성하기 위해 알고리즘은 먼저 대상 항목 i에 해당하는 사전 계산된 k 개의 가장 유사한 항목을 검색한다. 그런 다음 사용자 u가 구매한 k 항목 중 몇개를 이 교차점을 기반으로하여 예측이 기본 항목 기반 협업 필터링 알고리즘을 사용하여 계산한다.
여기서 품질과 성능(quality-performance)은 트레이드 오프 관계에 있다. 좋은 품질을 보장하려면 모델 크기가 커야하며, 이로 인해 위에서 설명한 성능 문제가 발생한다. 극단적인 경우 모델 크기 n을 가질 수 있는데, 이는 원래 계획과 똑같은 품질을 보장하지만 공간 복잡성이 높다. 그러나 모델 구축 단계에서는 가장 유사한 항목을 유지한다. 예측을 생성하는 동안 이러한 항목은 예측 점수에 가장 많이 기여한다. 따라서 모델 기반 접근 방식은 작은 크기로도 좋은 성능을 제공할 것이라고 가정한다. 이 논문 후반부에 가설을 검증한다. 특히 저장할 유사 항목의 수를 변경하여 모델 크기를 실험한다. 그런 다음 전체 시스템의 품질 및 성능에 대한 모델 크기의 영향을 확인하기 위해 예측과 응답 시간 계산 실험을 한다.
4 Experimental Evaluation
4.1 Data set
실험 데이터를 사용하여 항목 기반 추천 알고리즘을 평가한다.
Movie data
MovieLens는 1997년 가을에 나온 웹 기반 연구 추천 시스템이다. 매주 수백명의 사용자가 MovieLens에서 영화 추천을 한다. 현재 이 사이트에는 3500개 이상의 다른 영화에 대한 의견을 표명한 43000명 이상의 사용자가 있다. 데이터베이스에서 100,000개의 평가를 얻을 수 있을만큼 충분한 사용자를 무작위로 선택했다(20개 이상의 영화를 평가한 사용자만 고려). 데이터베이스를 트레인 셋과 테스트 셋으로 나누었다. x는 트레인과 테스트 세트로 사용되는 데이터의 비율을 결정하는 변수다. 즉 x=0.8은 80%가 트레인 셋으로 사용되고 20%가 테스트 셋으로 사용되었다는 것이다. 데이터 셋는 943개의 행(943명의 사용자)과 1682개의 열(최소 한명의 사용자가 평가한 1682개의 영화)이 있는 사용자 항목 행렬 A로 변환되었다. 실험을 위해 데이터 세트의 희소성 수준(sparsity level) 이라는 또 다른 요소도 고려한다. 데이터 행렬 R의 경우 로 정의된다. 따라서 Movie 데이터 세트의 희소성 수준은
다. 이 논문 전체에서 이 데이터 셋을 ML이라고 한다.
4.2 Evaluation Metrics
추천 시스템의 품질을 평가하기 위해 여러 유형의 metric을 사용했다. 주로 두 가지 클래스로 분류할 수 있다.
- 통계적 정확도 메트릭(Statistical accuracy metrics) 은 테스트 데이터 세트의 사용자 항목 쌍에 대한 실제 사용자 등급과 수치 추천 점수를 비교하여 시스템의 정확도를 평가한다. 평점과 예측 사이의 평균 절대 오차(MAE)는 널리 사용되는 측정 항목이다. MAE는 실제 사용자 지정값에서 추천 사항의 편차를 측정한 것이다. 각 등급-예측 쌍 <
>에 대해 이 메트릭은 둘 사이의 절대 오차를 구한다. 즉,
. MAE는 먼저 N개의 해당 등급-예측 쌍의 절대 오차를 합한 다음 평균을 계산하여 계산된다. 공식적으로,
MAE가 낮을수록 추천 엔진이 사용자 평점을 더 정확하게 예측한다. RMSE(Root Mean Squared Error) 와 상관 관계(Correlation) 는 통계적 정확도 메트릭으로도 사용된다.
- 의사 결정 지원 정확도 메트릭(Decision support accuracy metrics) 은 사용자가 모든 항목 집합에서 고품질 항목을 선택하는데 예측 엔진이 얼마나 효과적인지 평가한다. 이러한 측정 항목은 예측 프로세스를 이진 연산으로 가정한다. 항목이 예측되거나 (양호) 예측되지 않는다(나쁨). 이 관찰을 통해 사용자가 4 이상의 예측만 고려하도록 선택한 경우 항목의 예측 점수가 5점 척도에서 1.5 또는 2.5인지 여부는 관련이 없다. 가장 일반적으로 사용되는 의사 결정 지원 정확도 메트릭은 반전률, 가중치 오류, ROC 민감도이다.
MAE는 가장 일반적으로 사용되고 직접 해석하기 쉽기 때문에 예측 실험을 보고하기위한 평가 측정 항목이다. 이전 논문에서 MAE와 ROC가 예측 품질 측면에서 서로 다른 실험 계획의 동일한 순서를 제공함을 확인했다.
4.2.1 Experimental Procedure
Experimental steps
먼저 데이터를 트레인과 테스트 셋으로 나눴다. 매개 변수의 민감도를 결정했으며 민감도 플롯에서 이러한 매개 변수의 최적값을 수정하고 나머지 실험에 사용한다. 매개 변수 민감도를 결정하기 위해 훈련 데이터로만 학습하고, 이를 트레인과 테스트 부분으로 세분화하여 실험했다. 매번 다른 트레인과 테스트 셋을 무작위로 선택하여 MAE값에 평균을 취해 10-fold 교차 검증을 수행했다.
Benchmark user-based system
항목 기반 예측의 성능을 비교하기 위해 피어슨 최근접 이웃 알고리즘(Pearson nearest neighbor, 사용자-사용자)을 사용하는 협업 필터링 추천 엔진에 설정된 훈련 등급도 입력했습니다. 이를 위해 사용자 기반 CF 알고리즘을 구현하는 유연한 예측 엔진을 구현했다. 우리는 가장 잘 나온 피어슨 최근접 이웃 알고리즘을 사용하도록 알고리즘을 조정하고 성능에 대한 걱정없이 최고 품질의 예측을 제공하도록 구성했다(가능한 모든 이웃이 최적의 이웃을 형성하도록 고려함).
Experimental platform
모든 실험은 C를 사용하여 구현되었고 최적화 flag-06을 사용하여 컴파일되었다. 모든 실험은 속도가 600MHz이고 RAM이 2GB 인 Intel Pentium III 프로세서가 있는 Linux 기반 PC에서 실행되었다.
4.3 Experimental Results
품질 결과와 성능 결과를 보여준다. 추천 사항의 품질을 평가할 때 먼저 주요 실험을 실행하기 전에 일부 매개 변수의 민감도를 결정했다. 이러한 매개 변수에는 이웃 크기, 훈련/검정 비율 x, 다양한 유사성 측정의 효과가 있다. 다양한 매개 변수의 민감도를 결정하기 위해 트레인 데이터 셋에만 집중하여, 트레인과 테스트 부분으로 더 나누어 매개 변수를 학습하는데 사용했다.
4.3.1 Effect of Similarity Algorithms
3.1절에 설명된대로 세가지 유사성 알고리즘의 기본 코사인, 수정된 코사인, 상관 관계를 구현하여 테스트했다. 각 유사성 알고리즘에 대해 이웃을 계산하는 알고리즘을 구현하고 가중 합계 알고리즘을 사용하여 예측을 생성했다. 트레인 데이터에 대해 실험을 실행하고 테스트 세트를 사용하여 평균 절대 오차(MAE)를 계산했다.
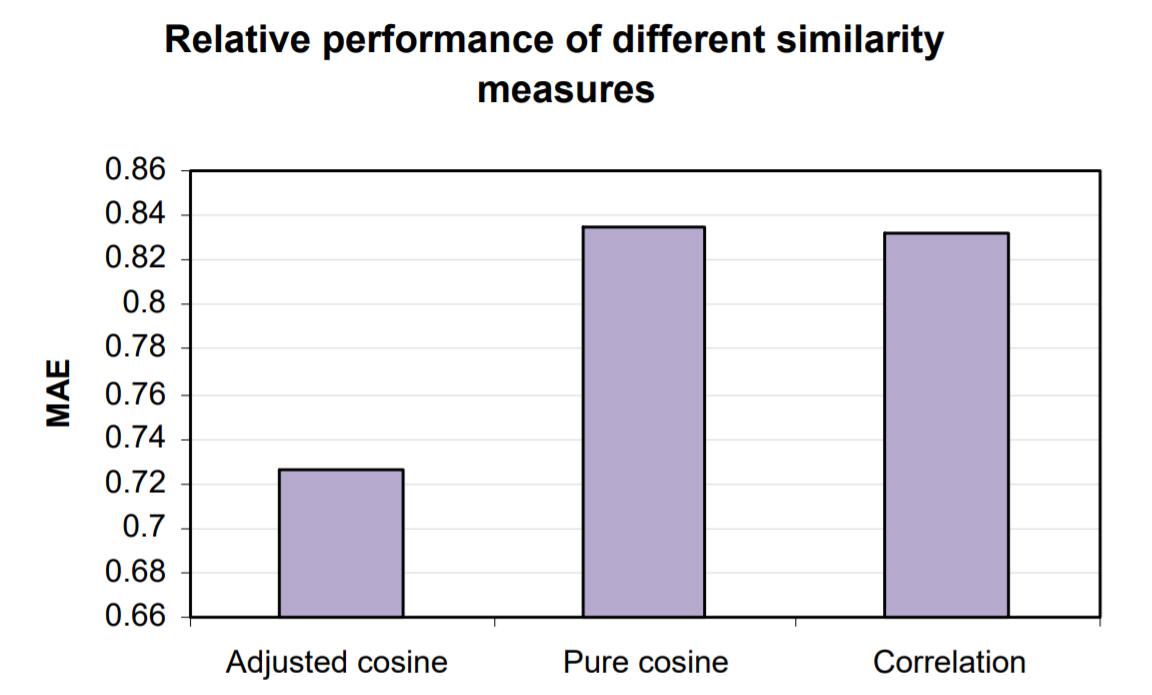
위 fig4는 실험 결과를 보여준다. 이 경우 MAE가 상당히 낮기 때문에 코사인 유사성 계산에 대한 사용자 평균을 상쇄하는 것이 분명한 이점이 있다. 따라서 나머지 실험에 대해 수정된 코사인 유사성을 선택한다.
4.3.2 Sensitivity of Training/Test Ratio
밀도 민감도(sensitivity of density)를 결정하기 위해 x의 값을 0.2에서 0.9까지 0.1 씩 증가시켰다. 이러한 각 트레인/테스트 비율값에 대해 두가지 예측 생성 기술(기본 가중 합계, 회귀 기반 접근 방식)을 사용했다.
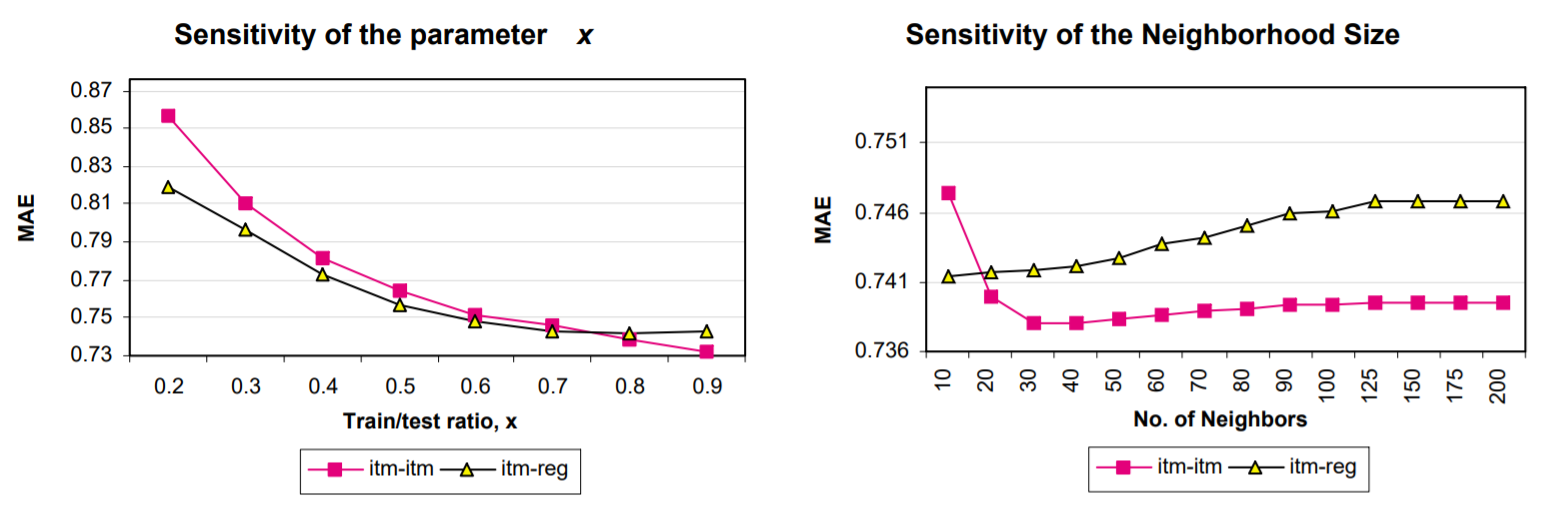
결과는 위 fig5에 나와있다. x를 증가시킬수록 예측의 질이 증가하는 것을 관찰한다. 회귀 기반 접근 방식은 x의 낮은 값에 대한 기본 계획보다 더 나은 결과를 보여 주지만 x를 증가시키면 품질이 계획 아래로 떨어지는 경향이 있다. 곡선에서 x=0.8을 후속 실험에 대한 최적값으로 선택한다.
4.3.3 Experiments with neighborhood size
이웃의 크기는 예측 품질에 상당한 영향을 준다. 매개 변수의 민감도를 결정하기 위해 사용할 이웃 수를 변경하고 MAE를 계산했다. 결과는 위 fig5에 나와있다. 그러나 두 가지 방법은 서로 다른 유형의 감도를 보여준다. 이웃 크기를 10에서 30으로 늘리면 기본 항목-항목 알고리즘이 향상되고 증가율이 감소하고 곡선이 평평해지는 경향이 있다. 반면 회귀 기반 알고리즘은 이웃 수가 증가함에 따라 예측 품질이 저하된다. 두가지 추세를 모두 고려하여 30을 최적의 이웃 크기로 선택한다.
4.3.4 Quality Experiments
매개 변수의 최적값을 얻은 후, 두 항목 기반 접근 방식을 벤치 마크 사용자 기반 알고리즘과 비교한다.
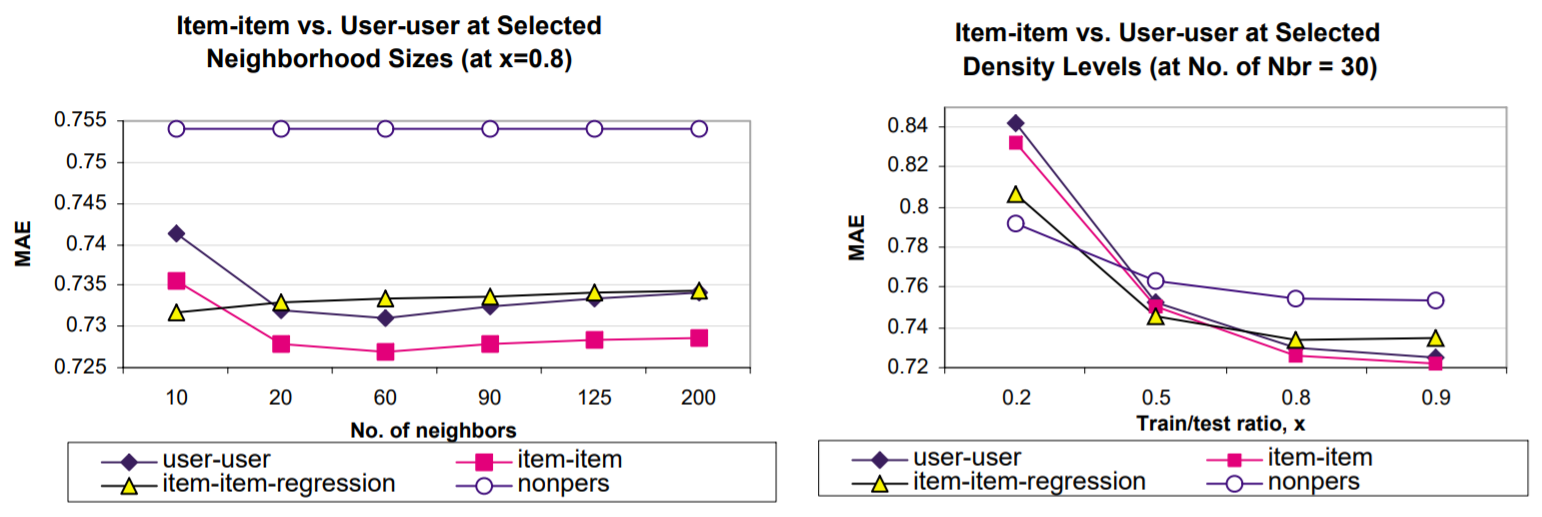
결과는 위 그림에 나타나있다. 기본 항목-항목 알고리즘 출력은 x(이웃 크기 = 30)의 모든 값과 이웃 크기(x = 0.8)의 모든 값에서 사용자 기반 알고리즘을 수행하는 것을 차트에서 확인할 수 있다. 예를 들어, x = 0.5에서 사용자-사용자 체계의 MAE는 0.755이고 항목-항목 체계는 MAE가 0.749다. 유사하게 60개의 사용자-사용자과 항목-항목 체계의 이웃 크기에서 MAE는 각각 0.732 및 0.726다. 그러나 회귀 기반 알고리즘은 흥미로운 동작을 보여준다. x값이 낮고 이웃 크기가 작으면 다른 두 알고리즘을 수행하지만 데이터 세트의 밀도가 증가하거나 이웃을 더 추가할수록 사용자 기반 알고리즘과 비교해도 성능이 저하된다. 또한 알고리즘을 [12]에 설명된 개인화되지 않은 알고리즘과 비교했다. 두 가지 결과가 있다. 첫째 항목 기반 알고리즘은 모든 희소성 수준에서 사용자 기반 알고리즘보다 더 나은 품질을 제공한다. 둘째, 회귀 기반 알고리즘은 희소한 데이터 셋에서 더 잘 수행되지만, 더 많은 데이터를 추가하면 품질이 저하된다. 회귀 모델이 고밀도 수준에서 데이터 과적합이 되기 때문으로 생각된다.
4.3.5 Performance Results
사용자 기반 알고리즘보다 항목 기반 알고리즘의 우수한 품질을 명확하게 설정한 후 확장성에 중점을 둔다. 앞서 논의했듯이 항목 기반 유사성은 더 정적이고 항목 이웃을 미리 계산할 수 있다. 이 모델의 사전 계산에는 특정 성능 이점이 있다. 시스템의 확장성을 높이기 위해 모델 크기의 민감도를 조사한 다음 모델 크기가 응답 시간과 처리량에 미치는 영향을 조사했다.
4.4 Sensitivity of the Model size
모델 크기가 예측 품질에 미치는 영향을 실험적을 통해 결정하기 위해 유사성 계산에 사용할 항목 수를 25개에서 200개까지 25개씩 늘렸다. 모델 크기 l은 l만 고려했음을 의미한다. 모델 구축에 대한 최상의 유사성 값은 나중에 예측 생성 프로세스에 사용된 k에서 k<l입니다. 트레인 데이터 셋을 사용하여 서로 다른 모델 크기를 사용하여 항목 유사성을 미리 계산한 다음 가중 합계 예측 생성 기술 만 사용하여 예측을 제공했다. 그런 다음 테스트 데이터 세트를 사용하여 MAE를 계산하고 값을 플로팅했다. 전체 모델 크기(모델 크기=항목 수)와 비교하기 위해 모든 유사성 값을 고려하여 동일한 테스트를 실행하고 예측 생성을 위해 최상의 k를 선택했다. 세가지 x 값(트레인/테스트 비율)에 대해 전체 프로세스를 반복했다.
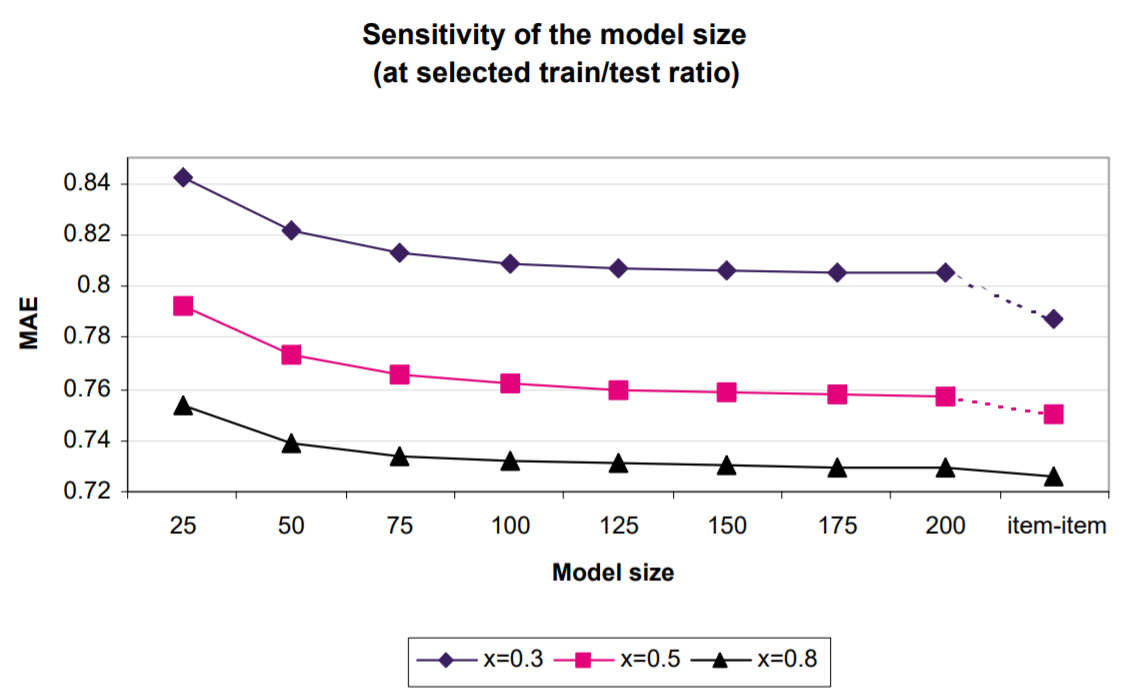
위는 서로 다른 x값에 대한 그래프를 보여준다. 모델 크기를 늘리면 MAE값이 좋아진다. 초반에는 개선 폭이 크지만, 모델 크기를 늘리면 점차적으로 느려진다. 이 그래프에서 항목의 일부만 사용하여 높은 정확도를 얻을 수 있다는 것을 보인다. 예를 들어, x=0.3에서 전체 item-item은 MAE가 0.7873이지만, 모델 크기를 25로만 사용하여 MAE값이 0.842이다. x=0.8에서 더 좋은 결과를 낸다. MAE는 0.726이었지만, 모델 크기가 25이면 MAE는 0.754이고, 모델 크기가 50이면 MAE가 0.738이다. 즉, x=0.8에서 각각 1.9%와 3%의 아이템만을 사용하여 전체 item-item 체계의 정확도의 96%와 98.3%의 결과를 낼 수 있었다!
4.4.1 Impact of the model size on run-time and throughput
모델 크기가 작아도 예측 품질이 상당히 좋기때문에 시스템의 런타임과 처리량에 중점을 둔다. 전체 테스트 셋에 대한 예측을 생성하는데 필요한 시간을 기록하고 다양한 모델 크기를 사용하여 차트에 표시했다. 다른 x값에서 런타임을 플로팅했다.
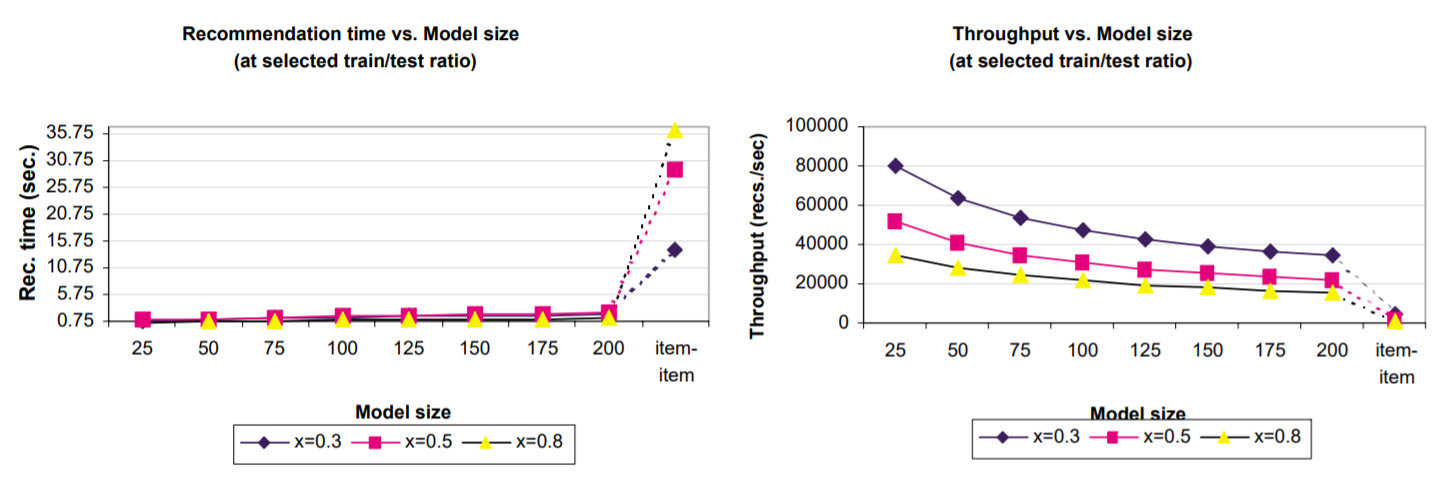
x=0.25에서 전체 시스템은 25,000개의 테스트 케이스에 대해 예측했다. 그래프에서 우리는 작은 모델 크기와 전체 item-item 예측 케이스 간의 런타임에서 상당한 차이를 보인다. x=0.25일 때, 런타임은 기본 item-item 케이스의 경우 14.11이지만, 모델 크기 200의 경우 2.002초입니다. 이 차이는 x=0.8에서 더욱 두드러진다. 여기서 모델 크기 200은 1.292초만 필요하고 기본 항목-항목 케이스는 36.34초가 필요하다.
이러한 런타임 수치는 워크로드(work-load) 크기, 즉 생성될 예측수가 다른 여러 트레인/테스트 비율에 대해 계산했기 때문에 오해의 소지가 있을 수 있다(x=0.3에서 알고리즘은 트레인 데이터로 3만 개의 평가를 사용하고 나머지 70,000개의 평가를 테스트 데이터로 사용하여 시스템에서 생성된 예측을 실제 평가와 비교한다). 수치를 비교할 수 있도록 모델 기반 및 기본 item-item에 대한 처리량 (초당 생성된 예측)을 계산한다. 위 그래프는 이러한 결과를 보여준다. x=0.3이고 모델 크기가 100인 경우 시스템은 1.487초 동안 70,000 개의 등급을 생성하여 47,361의 처리량 비율을 생성한다. 여기서 기본 item-item은 4961의 처리량만 생성했습니다. x=0.8에서 이 두 숫자는 각각 21,505와 550이다.
4.5 Discussion
item-item 협업 필터링의 실험적 평가에서 몇 가지 중요한 관찰을 수행한다. 첫째, item-item는 user-user(k- 최근 접 이웃)보다 성능이 더 좋다. 품질 향상은 다양한 이웃 크기와 트레인/테스트 비율에서 일정하지만, 개선의 폭은 크지 않다. 두 번째 항목 이웃이 상당히 정적이고 잠재적으로 사전-계산 될 수 있어 온라인 성능이 높다. 또한 모델 기반 접근 방식으로 인해 항목의 작은 하위 집합만 유지하고 합리적으로 우수한 예측 품질을 생성할 수 있다. 실험 결과는 그 주장을 뒷받침한다. 따라서 item-item은 E-커머스를 위한 추천 시스템의 가장 중요한 두 가지 문제인 예측 품질과 고성능을 처리할 수 있다.
5 Conclusion
추천 시스템은 사용자 데이터베이스에서 비즈니스를 위한 부가가치를 창출할 수 있는 기술이다. 사용자가 좋아하는 항목을 찾아서 사용자에게 도움이 되고, 반대로 더 많은 판매를 하여 비즈니스를 돕는다. 추천 시스템은 웹에서 E-커머스에서 중요한 도구가 되고 있다. 추천 시스템은 기존 기업 데이터베이스에 있는 방대한 양의 사용자 데이터로 인해 스트레스를 받고 있으며 웹에서 사용할 수 있는 사용자 데이터의 양이 증가함에 따라 더욱 스트레스를 받을 것이다. 추천 시스템의 확장성을 획기적으로 향상시킬 수 있는 새로운 기술이 필요하다. 이 논문에서 CF 기반 추천 시스템을 위한 새로운 알고리즘을 제시하고 평가했다. 결과는 항목 기반 기술이 CF 기반 알고리즘을 대규모로 확장하는 동시에 고품질 추천 사항을 생성한다.
Leave a comment