[논문리뷰] Abstractive Summarization of Spoken and Written Instructions with BERT
ABSTRACT
음성 요약은 흐름의 자발성, 유창하지 않음과 같이 문서 요약에서는 발생하지 않는 문제가 있다. 이 연구는 BERTSum 모델을 대화 데이터에 처음 적용했다. 다양한 주제에 대해 설명된 교육용 영상의 추상 요약을 생성한다. 어휘를 풍부하게 하기위해, 영어로 쓰여지거나 말해진 대규모 교차 도메인 데이터 셋으로 모델을 사전 학습시키고 전이 학습을 사용한다. 또한 ASR 시스템의 출력에서 문장 분할과 구두점을 복원하기위해 전처리한다. 모델 평가는 How2, WikiHow 데이터 셋에 대한 ROUGE, Content-F1 점수를 사용하고, 비교를 위해 HowTo100M와 YouTube에서 무작위로 선택된 요약을 사람이 평가한다. 블라인드 평가 결과, 사람이 작성한 요약과 유사한 수준의 텍스트 유창성과 유용성을 보인다. 스타일과 주제가 다양한 WikiHow 기사에 적용할 때 현재 SOTA를 능가하지만, CNN/DailyMail 데이터에서는 성능 회귀가 없었다. 다양한 스타일과 도메인에서 일정한 성능을 내기(generalizability) 때문에 인터넷 콘텐츠의 접근성과 검색 가능성을 향상시킬 수 있다.
CSS CONCEPTS
- Human-centered computing → Accessibility system and tools;
- Computing methodologies → Information extraction
1. INTRODUCTION
이 논문의 목적은 사용자-생성 온라인 콘텐츠에 더 쉽게 접근할 수 있도록 하는 것이다. 사용자가 정보를 소화 할 수 있도록 자동 요약 도구를 개선한다. 많은 온라인 콘텐츠는 다양한 구어, 필터 단어, 전문 용어를 사용한다. 따라서 텍스트 요약은 중요한 정보를 추출할 뿐만 아니라 보다 일관되고 구조화 된 출력을 내야한다. 대화 형식과 문서 형식에 추출 요약과 추상 요약을 모두 사용한다. 추출 요약은 문서에서 가장 중요한 문장을 식별하기 위한 간단한 분류 문제로, 요약에 문장이 포함되어야 하는지 여부를 분류한다. 반면에 추상 요약은 텍스트에서 찾을 수 없는 새로운 단어와 구를 포함하는 요약을 생성하는 언어 생성 기능이 필요하다. 구어 텍스트를 요약할 때 유창성, 명료성, 반복 문제를 해결해야한다. 이것은 ASR(speech-to-text) 입력에서 음성 언어를 요약하기 위해 BERT 기반 모델을 사용하는 첫번째 시도다. How2 기사와 영상으로 다양한 도메인에서 사용할 수 있는 일반화된 모델을 개발하는 것이 목표다. 이 문제를 성공적으로 해결하면 인간과 봇 간의 대화 시스템 대화 요약과 같이 요약 모델을 이 영역의 다른 응용 프로그램으로 확장 할 수 있다.
논문은 다음과 같은 순서로 진행된다.
- 최첨단 요약 방법 검토
- 훈련에 사용되는 텍스트, 대화 및 요약 데이터 세트에 대한 설명
- BERT 기반 텍스트 요약 모델 적용 및 교육용 비디오에서 자동 생성된 스크립트에 대한 미세 조정
- 이전 연구에서 사용된 지표 외에 평가 방법에 대한 개선 제안
- 실험 결과 분석 및 벤치 마크와 비교
3. METHODOLOGY
3.1 Data Collection
다양한 텍스트에 걸쳐 일관된 요약을 구성하는 모델이 더 많은 양의 데이터에 대한 학습의 이점을 누릴 것이라고 가정한다. 표1은 다양한 텍스트 및 비디오 데이터셋 크기를 보여준다. 모든 학습 데이터 셋에는 문서화된 요약이 포함된다. 데이터는 비공식적 내용부터 형식적 내용, 단일 문장에서 짧은 단락까지 다양하다.
- CNN/DailyMail Dataset : 기사 당 평균 길이가 119 단어, 요약 당 83 단어로 작성된 뉴스 기사와 주요 기사의 조합을 포함한다. 기사는 2007년부터 2015년까지 수집되었다.
- Wikihow Dataset : : 200,000개 이상의 단일 문서 요약이 포함된 대규모 텍스트 데이터 세트다. Wikihow는 wikihow.com에서 ‘코로나 바이러스 불안에 대처하는 방법’부터 ‘우노 플레이 방법’에 이르기까지 다양한 주제로 wikihow.com에서 컴파일된 최신 ‘How ToâĂŹ’지침 텍스트 모음을 통합한 것이다. 기사 내 각 단락의 첫 번째 문장을 연결하여 요약을 구성한다.
- How2 Dataset : 이 YouTube 편집에는 평균 90초 길이의 비디오 (8,000개의 영상-약 2,000 시간)와 대본 길이로 291개의 단어가 있다. 여기에는 청중을 극대화하기 위해 요약을 작성하도록 영상 소유자가 지시한 사람이 작성한 요약이 포함된다. 요약은 2~3개의 문장으로 구성되며 평균 길이는 33단어다.
Wikihow, How2와 같은 교육용 데이터셋이 개발 되었음에도 불구하고 요약의 발전은 사람이 주석이 달린 대본 및 요약의 가용성에 의해 제한되었다. 이러한 데이터셋은 확보하기 어렵고 생성하는데 비용이 많이 들기 때문에 종종 단일 작업 및 고도로 구조화 된 데이터를 반복적으로 사용하게된다. How2 데이터셋의 샘플에서 볼 수 있듯이 특정 길이와 구조화 된 요약의 영상만 학습 및 테스트에 사용된다. 연구 범위를 확장하기 위해 자동 생성된 교육용 영상 스크립트와 사람이 선별한 설명으로 기존 레이블이 지정된 요약 데이터셋 보완했다.
게시된 HowTo100Million과 몇가지 ‘How-To’및 Do-It-Yourself YouTube 재생 목록을 결합하여 얻은 새로운 데이터셋을 소개한다. 이 모델을 사용하는 것의 타당성을 테스트하기 위해 해당 요약이나 사람이 만든 주석이 없는 다양한 대화 텍스트에서 영상을 선택했다. 선택된 ‘How-To’ 및 ‘DIY’ 데이터 셋은 주류 소프트웨어 다운로드에서 주택 개선에 이르기까지 다양한 주제를 다루는 교육용 재생 목록이다. ‘How-To’ 재생 목록은 영상의 기계 음성 해설을 사용하여 지시를 돕고 ‘DIY’ 재생 목록에는 사람이 발표한 영상이 있다. HowTo100Million 데이터 셋은 140개 카테고리에 걸쳐 설명된 교육용 영상에서 가져온 1억개 이상의 영상 클립으로 구성된 대규모 데이터 셋이다. 데이터 셋은 모든 카테고리의 샘플을 통합하고 YouTube에서 제공하는 자동 생성 자막을 활용한다.
3.2 Preprocessing
input 데이터가 다양하고 복잡하기 때문에, 일반적인 포맷으로 데이터를 정렬하는 전처리 파이프라인을 만들었다. 모델 학습에 영향을 준 구두점, 잘못된 단어, 관계없는 소개에 대한 문제가 있었다. 이런 문제로, 모델이 text segment를 잘못 나누고 좋지 않은 요약 결과를 냈다. 예외적인 경우, 모델은 요약된 결과를 내지 못했다. 사람이 작성한 요약의 유창성과 일관성을 유지하기 위해, 다음과 같이 문장 구조를 정제했다. 오픈소스 라이브러리(spacy, nltk)로 entitiy detection을 실행한다. nltk는 introduction을 제거하고, 요약모델의 인풋을 익명화한다. 문장을 나누고 모든 데이터셋에 Stanford Core NLP toolkit을 토큰화하고, See et.al과 같은 방법으로 데이터를 전처리한다.
3.3 Summerization models
Text Summarization with Pretrained Encoders에 제안된 BertSum 모델을 사용한다. 추출(Extractive) 요약과 추상(Abstractive) 요약을 동시에 포함하고 있고, 이는 BERT를 기반으로 문서 수준의 인코더를 사용한다. transformer 구조는 무작위로 초기화된 Transformer decoder로 pretrained BERT 인코더에 적용된다. 이는 두가지 학습률(learning rate)를 사용한다.: 인코더에는 작은 학습률을 사용하고, 디코더에는 학습을 향상시키기 위해 더 큰 학습률을 사용한다.
How2 데이터 셋에서 5,000개 영상 샘플에 추출모델을 학습시켜 베이스라인을 만든다(4-GPU Linux 사용). 처음에는 BERT-base-uncased를 10,000 스텝에 적용하고, 가장 좋은 성능을 낼 수 있는 epoch 크기를 골라서 요약 모델과 BERT 레이어 미세조정(fine tuned)한다. 이 초기 모델에 How2와 WikiHow에 개별적으로 추상 요약 모델을 추가적으로 학습한다.
추상 요약 모델의 가장 좋은 버전은 CNN/DailyMail, Wikihow, How2을 모두 합친 데이터 셋으로 만들어졌다. 이 데이터 셋은 535,527개의 예시와 210,000개의 스탭으로 되어있다. 사이즈 50의 배치 크기를 사용하고, 20 에폭으로 모델을 학습한다. 데이터 셋의 순서를 조정하여, 요약의 유창성을 향상시킬 수 있다. 이전의 연구에서 언급한 것처럼, 기존의 모델은 1억 8천만개 이상의 모수가 있고, 인코더와 디코더 각각 $\beta_1=0.9$, $\beta_2=0.999$로 Adam 옵티마이저를 사용한다. learning rate는 인코더는 0.002이고, 디코더는 0.2를 사용한다. 이것은 디코더가 안정되는 동안, 인코더가 더 정확한 기울기로 훈련되었는지 확인한다. 결과는 Section 4에 나와있다.
사람이 배우는 것과 같이, 모델에서도 훈련 순서가 중요하다고 가정한다. 자연어처리에 curriculum learning을 적용하는 방법은 관심이 증가했다. 더 복잡하지만 예측 가능한 언어 구조4로 이동하기 전, 고도로 구조화된 샘플을 학습한다. 텍스트 스크립트를 훈련한 후, 비디오 스크립트를 진행한다다. 이 스크립트는 임시 흐름과 대화 언어에 대한 추가적인 문제가 된다.
3.4 Scoring of results
결과는 추상 요약에서 일반적으로 사용하는 ROUGE를 이용해서 스코어링 된다. 요약이 잘되면 높은 ROUGE 점수가 나올거라 기대했지만, 결과에서는 요약이 잘 안됐지만 ROUGE가 높고, 요약이 잘됐지만 ROUGE 점수는 낮았다.(Figure 10)
Content F1 스코어링을 추가했다. 이 메트릭은 컨텐츠의 관련성에 초점을 맞췄다. ROUGE와 비슷하게, Content F1 스코어는 가중 f-score와 잘못된 단어 순서로 요약한다.
작성된 요약없이 구절을 스코어링하려면, Python, Google Forms, Excel 스프레드 시트를 사용하여 평가 프레임워크로 사람의 판단을 조사했다. 사람의 판단이 포함된 요약들은 편향되지 않기 위해 랜덤하게 샘플링 된다. 사람과 기계가 생성한 요약 간에 비대칭 정보를 줄이기 위해 대문자를 제거했다. 두가지 질문을 했다.: AI와 인간이 생성한 설명과 구별하기 위한 튜링 테스트 질문이다. 두번째는 요약에 대한 품질을 선택하는 것이다. 다음은 명확성을 판단하기위한 기준의 정의이다.
- 유창성(Fluency) : 텍스트가 자연스러운 흐름을 가지고 있나?
- 유용성(Usefulness) : 사용자가 영상 시청에 시간을 할애할지 여부를 결정할 수 있는 충분한 정보가 있나?
- 간결함(Succinctness) : 텍스트가 간결하게 보이나? 아니면 중복성이 있나?
- 일관성(Consistency) : 텍스트에 모호하거나 혼란스럽거나 모순되는 문장이 있나?
- 현실성(Realisticity) : 단어 조합이 복잡하고 이상하거나, “정상”으로 보이지 않는 것이 있나?
요약 등급은 다음과 같다.: 1:나쁨 2:평균이하 3:평균 4:좋음 5:매우좋음
4. EXPERIMENTS AND RESULTS
4.1 Training
BertSum 모델은 CNN/DailyMail 데이터 셋에서 가장 좋은 성능을 냈다. BertSum 모델은 추출 요약과 추상 요약 모두를 지원한다. 베이스라인은 CNN/DailyMail에서 How2 video로 사전 학습된 추출 요약 BertSum 모델에서 얻은 것이다. 그러나 모델은 매우 낮은 점수를 냈다. 모델에서 생성한 요약은 일관되지 않고 반복적이며 정보가 없었다. 안좋은 성능에도 불구하고, 모델은 How2 video 내의 건강 하위 도메인에서 더 잘 수행되었다. CNN/DailyMail에 의해 생성된 뉴스에서 과도한 보도의 증상이라고 설명했다. 추출 요약은 가장 좋은 모델이 아니다.: 대부분의 YouTube 영상은 캐주얼한 대화 스타일인 반면 요약은 더 형식적이다. 성능 향상을 위해 추상 요약으로 바꿨다.
추출 요약 모델은 사전 학습된 BERT 인코더와 무작위로 초기화 된 Transformer 디코더를 합친 인코더-디코더 구조를 사용한다. 인코더 부분이 매우 낮은 학습률로 거의 동일하게 유지되는 특수 기술을 사용하고 디코더가 더 잘 학습할 수 있도록 별도의 학습률을 생성한다. 일반화 가능한 추상 모델을 만들기 위해 먼저 대규모 뉴스 코퍼스를 학습하여, 구조화 된 텍스트를 이해하도록 했다. 그런 다음 모델을 How-To 도메인에 노출하는 Wikihow를 도입했다. 마지막으로 How2 데이터 세트에 대해 학습하고 검증하여 모델의 초점을 선택적으로 구조화된 형식으로 좁혔다. 순서가 지정된 훈련 외에도 무작위로 균질한 샘플 세트를 사용하여 모델 훈련을 실험했다. 순서가 지정된 샘플로 훈련하는 것이 무작위 샘플보다 더 좋은 결과를 냈다.
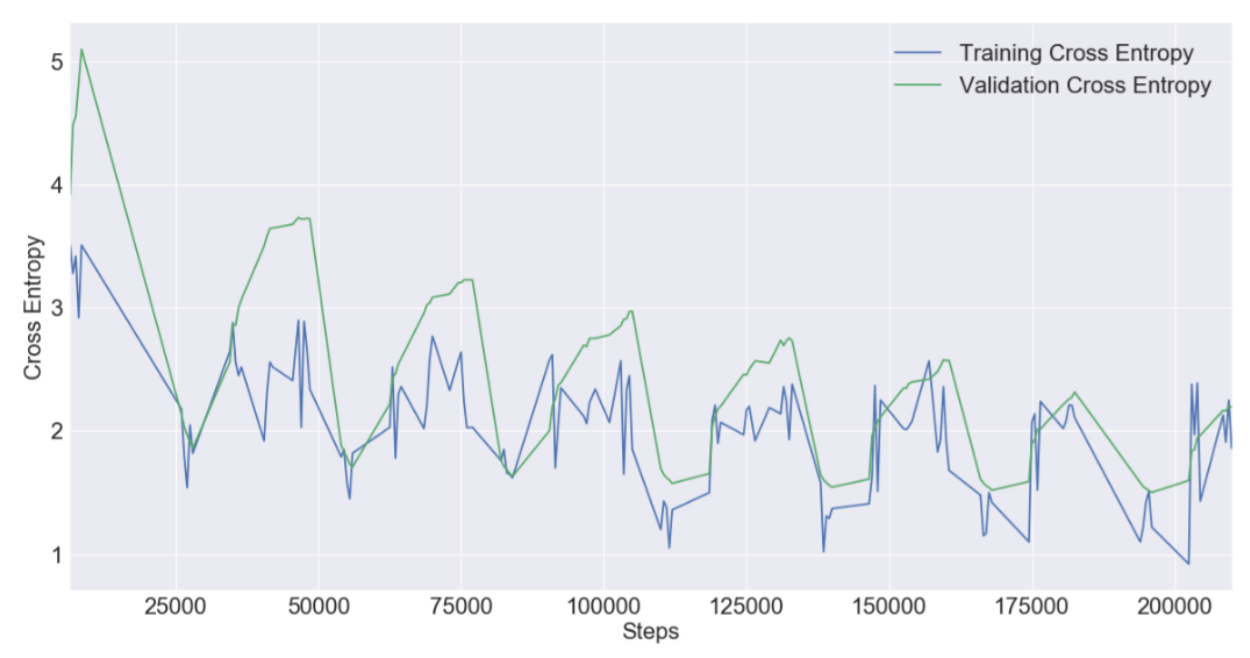
위 교차 엔트로피 차트를 보면, 과적합이나 과소적합되지 않았음을 확인할 수 있다. 훈련 및 검증 라인의 수렴으로 좋은 적합성을 나타낸다.
위 그림은 훈련 및 검증 세트에 대한 모델의 정확도 메트릭을 보여준다. 모델은 훈련 데이터에 대해 How2 데이터로 검증한다. 모델은 더 많은 단계를 통해 예상대로 향상한다.
4.2 Evalutation
CNN/DailyMail로 학습된 BertSum은 해당 데이터셋에 적용될 때 최상의 결과를 냈지만, How2 데이터셋에 테스트 했을 때는 성능이 좋지 않고 일반화가 되지 않았다(표3-1행). 데이터를 보면 첫번째나 두번째 문장을 선택하는 경향이 있다. 텍스트에서 introductions를 지우는게 ROUGE 스코어를 증가하는데 도움이 됐다. 3.2에서 설명한 전처리를 적용한 후, 몇 가지 ROUGE 포인트를 개선했다. 또 모델에 익숙하지 않은 희귀 단어에서 발생하는 것을 관찰해서 output에 단어 중복 제거를 추가해서 모델을 개선했다. 22.5 ROUGE-1 F1과 20 ROUGE-L F1 보다 더 높은 점수를 받지 못했다(초기 점수는 CNN/DailyMail로 학습하고 How2로 테스트 함). 개별 요약의 점수와 텍스트를 봤을 때, 의학과 같은 일부 주제에서 더 나은 성과를 내지만 스포츠와 같은 다른 주제에서는 낮은 점수를 받았다.
사전 학습된 비디오 스크립트와 뉴스 스토리의 대화 스타일 차이가 모델 output에 영향을 준다. CNN/DailyMail에 대해 사전 훈련된 추출 요약 모델의 초기 적용에서 스타일 오류가 뚜렷하게 나타났다. 요약을 생성할 때, 초기 소개 문장이 중요하다고 간주했다([15]에서 N-lead로 표현됐고, 여기서 N은 중요한 첫 문장의 수입니다). 모델은 “hi”와 “hello, the is
How2에 추상 BertSum을 재학습하는 것은 흥미롭고 기대하지 않았던 결과를 보여줬다. - 모델은 도메인에 관계없이 대부분의 영상에서 흔히 볼 수 있는 동일한 의미없는 유행어 요약을 생성하게 됐다.
다음 실험 시리즈에서는 학습을 위해 확장된 데이터 세트를 사용했다. BertSum 모델 1(표3)의 결과에 대한 ROUGE 점수의 차이가 BertSum 모델2 및 3과 크게 다르지 않지만 사람의 관점에서 요약의 품질은 질적으로 다르다.
How2 영상에서 최고의 결과(표3에서 실험4)는 레이블이 달려있는 데이터셋(CNN/DM, WikiHow, How2)을 구성을 유지하는 순서로 모두 활용해서 달성했다. 최고의 ROUGE 스코어는 뉴스 문서[14]의 최고의 결과와 비슷하다(표3에서 9행).
마지막으로 WikiHow에서 최고의 결과를 얻었다. WikiHow의 Rouge-L 최고 점수는 26.54이고, 이번 BERT 추상 요약 모델은 36.8을 기록했다. Poniter Generator+Coverage 모델과 비교하면, Rouge-1과 Rouge-L 각각 10씩 증가했다. 전체 How2, WikiHow, CNN/DailyMail에 대한 순서화된 학습에 BertSum을 사용하여 WikiHow에 대해 동일한 결과 테스트를 받았다.
초기 결과를 통해 콘텐츠에 대한 명확한 아이디어를 제공하는 유창하고 이해하기 쉬운 동영상 설명을 얻었다. BERT를 사용함에도 불구하고, 다른 연구의 점수를 능가하지 못했다. 그러나 요약은 How-To 도메인에서 요약을 보는 사용자에게 더 유창하고 유용한 콘텐츠로 보인다. 예시는 [Appendix: C]에 있다.
추상 요약은 일부 영상 대본에서 나타난 음성-텍스트(speech-to-text) 오류의 영향을 줄이는 데 도움이 되었다. 특히 이 프로젝트의 일부로 생성한 추가 데이터 세트에서 자동 생성된 자막 처리 (How2 영상의 대본이 검토되었으며 수동으로 수정되었으므로 철자 오류가 덜 일반적이다)에 효과적이다. 예를 들면, .
일반적으로 설명에 중복성이 많기 때문에, 모델은 의미있는 요약을 생성하기에 충분한 컨텍스트를 파악할 수 있다. 사람의 감독없이 ASR-생성된 스크립트에서 자주 발생하는 맞춤법 오류의 영향으로 인해, 요약 내용이 영상 주제와 일치하지 않는 상황은 없었지만, Spacy로 전처리 단계에서 구두점 오류를 수정하여 문장 간의 올바른 경계를 만드는 것은 큰 차이를 보였다.
이러한 결과로 모델이 사람이 작성한 설명에 비슷한 좋은 결과를 생성한다고 보여졌다. 요약 품질의 차이를 분석하기 위해 전문가의 도움을 받아 요약과 사용자가 YouTube 영상에 제공하는 설명 사이의 대화 특성을 평가했다. 30명 이상의 자원 봉사자로 구성된 다양한 그룹을 모집하여 선별된 대화형 데이터 세트에서 모델 및 영상 설명에 의해 생성된 무작위로 선택된 25개의 영상 요약 세트를 평가했다. 두가지 유형의 질문을 만들었다.: 하나는 유명한 Turing 테스트의 한 버전으로 AI를 인간이 선별한 설명과 구별하기 위한 도전이었고 3.4 절에 설명된 프레임 워크를 사용했다. 참가자는이 분류 작업에서 이러한 요약 출력 중 일부, 전부 또는 일부가 기계로 생성되지 않았을 가능성이 동일하다는 사실을 인식했다. 두 번째 질문은 대화의 질을 다루는 등급 분포를 수집한다. 두 평가에 대한 집계 결과는 그림 6-8에 나와 있다. 튜링 테스트 답변에서 만점 0 점을 관찰합니다. 결과에는 많은 false positive와 false negative가 포함되어있다[Appendix: D].
테스트 출력의 품질은 YouTube 요약과 비슷하다. 추상 요약은 문법적으로 정확하고 일관성 없는 문장을 생성하는 경향이 있기 때문에 “현실적인” 텍스트가 주요 성장 기회다. 인간 저자는 언어 사용 오류를 만드는 경향이 있다. 추상 요약 모델을 사용하면 영상 작성자의 문법과 관련된 몇 가지 문제를 완화할 수 있다.
5. CONCLUSION
연구의 업적은 교육 과정 전반에 걸쳐 교육용 영상 스크립트의 요약을 위해 BertSum 모델을 일반화하기 위해 확인한 여러 문제를 해결한다.
- 훈련 데이터와 매개 변수의 다양한 조합이 BertSum 추상 요약 모델 성능에 미치는 영향을 보였다.
- 요약하기 전에 자동 생성된 자막 스크립트에 대한 새로운 전처리 단계를 고안했다.
- YouTube 사용자가 생성한 무작위 샘플링 설명에 가까운 품질 수준으로 BertSum 추상 요약 모델을 자동 생성된 교육용 영상 스크립트로 일반화했다.
- ROUGE, BLEU, Content F1을 강화하여 보다 실행 가능하고 객관적인 점수를 생성하는 블라인드 공정한 검토를 위한 새로운 프레임워크를 설계하고 구현했다.
위에 나열된 모든 아티팩트는 이후 연구를 위해 저장소에서 사용할 수 있다. 전반적으로 아마추어 해설 교육용 영상에서 얻은 결과를 통해 경쟁 품질의 ASR (speech-to-text) 스크립트에서 YouTube에서 인간이 선별한 설명에 대한 요약을 생성하는 훈련된 모델을 만들 수 있다. 레이블이 지정된 요약 데이터 세트의 가용성이 제한되어 있으므로 향후 계획은 사람이 선별한 요약으로 사람 평가 프레임워크를 확장하기 위해 몇 가지 벤치 마크 모델을 만드는 것이다. 비공식적이고 공식적인 대화 스타일 전반에 걸친 일반화된 요약의 성공을 감안할 때 이러한 요약 모델을 인간-챗봇 대화에 적용하는 것을 조사하는 것이 향후 작업을 위한 중요한 방향이다.
Leave a comment