[논문리뷰] Deep Neural Networks for YouTube Recommendations
2016년 구글 리서치가 공개한 논문이다. 이 논문에서는 YouTube라는 영상 플랫폼의 특징을 고려한 추천시스템을 설명하고 있다.
중고거래 플랫폼 당근마켓은 상품 추천에 이 알고리즘을 사용하고 있다. 수많은 사용자에게 실시간 처리가 가능하도록 만들어졌기 때문에, 당근마켓 외에도 다양한 회사에서 사용될 것으로 생각된다.
ABSTRACT
- deep candidate generation model
- separate deep ranking model
#추천시스템; #딥러닝; #확장성
1. INTRODUCTION
Youtube 추천시스템은 세가지 관점을 고려해서 만들었다.
- 규모(Scale) : 작은 규모에서 만들어진 추천 알고리즘은 YouTube에 적용하면 작동하지 않았다. YouTube에 특화된 알고리즘이 필요할 뿐만 아니라 효율적인 서버 시스템이 필요하다.
- 새로움(Freshness) : 유투브는 끊임없이 동영상이 업로드 되기 때문에 후보군(코퍼스)이 일정하지 않다.
- 잡음(Noise) : 사용자가 시청한 동영상은 전체 동영상의 극히 일부(sparsity)이고, 사용자가 시청한 동영상을 마음에 들어하는지 정확한 피드백이 없다.
이전 연구들은 대부분 matrix-factorization을 사용하고 딥러닝을 이용한 연구는 상대적으로 적었다.
2. SYSTEM OVERVIEW
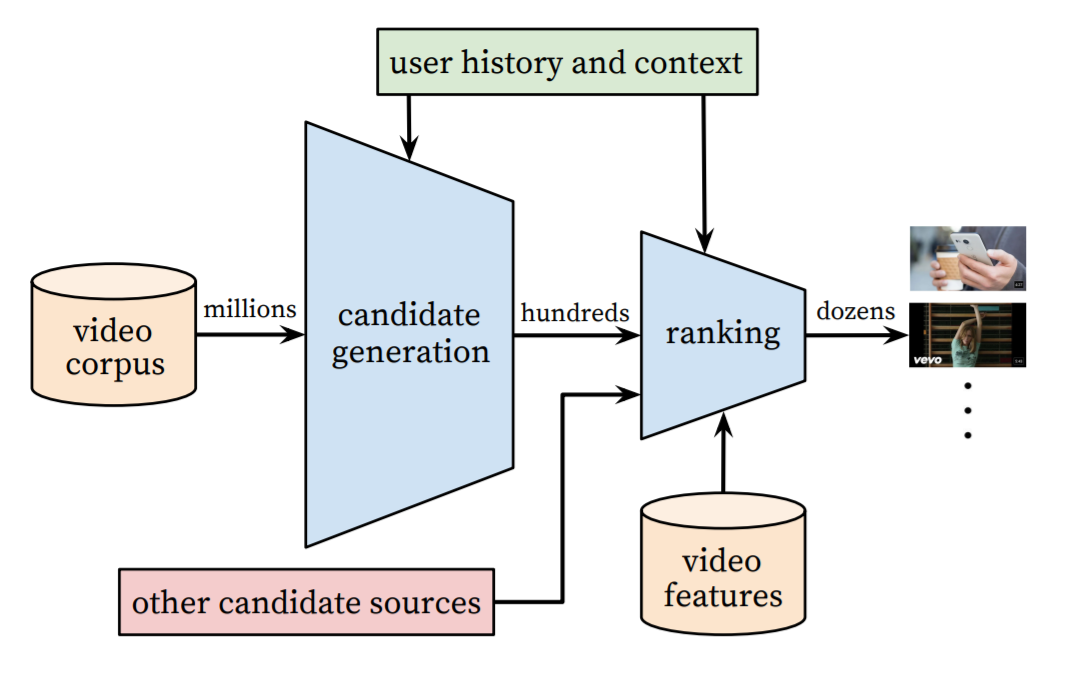
위 그림이 추천시스템의 전체적인 구성이고, 파란색 블럭이 실제 추천을 진행하는 단계이다.
-
후보 생성 네트워크 (The candidate generation network)
- 협동 필터링(collaborative filtering)으로 넓은 의미의 개인화를 제공한다.
- 사용자 간의 유사성은 coarse features 관점에서 표현된다. 여기서 말하는 coarse features는 비디오 시청한 ID, 검색 쿼리 토큰, 인구통계정보를 의미한다.
-
랭킹 네트워크 (The ranking network)
- 상대적인 중요도를 구분하여 세밀한 추천 목록 생성한다.
- 여기에는 재현율(recall, 실제 True 중 True로 예측한 비율)이 사용된다.
이 과정에서 사용자의 시청기록과 맥락을 고려한다.
모델 성능은 두가지 방법으로 측정한다.
- Offline Experiments : precision, recall, ranking loss
- Live Experiments : 클릭률, 시청시간
두 실험의 결과가 항상 똑같진 않다. 1번 방법의 메트릭으로 나타나지 않는 실제 결과를 A/B 테스트를 통해 알아보고자 2번째 방법을 병행한다.
3. CANDIDATE GENERATION
3.1 Recommendation as Classification
추천 문제를 엄청나게 많은 클래스로의 다중 분류 문제로 재정의한다.
\[K(a,b) = \int \mathcal{D}x(t) \exp(2\pi i S[x]/\hbar)\]Efficient Extreme Multiclass
실제 레이블과 샘플링 된 네거티브 클래스에 대해 교차 엔트로피 손실이 최소화 된다.
사용자에게 보여줄 top N개를 뽑는다. 수백만개의 항목들
3.2 Model Architecture
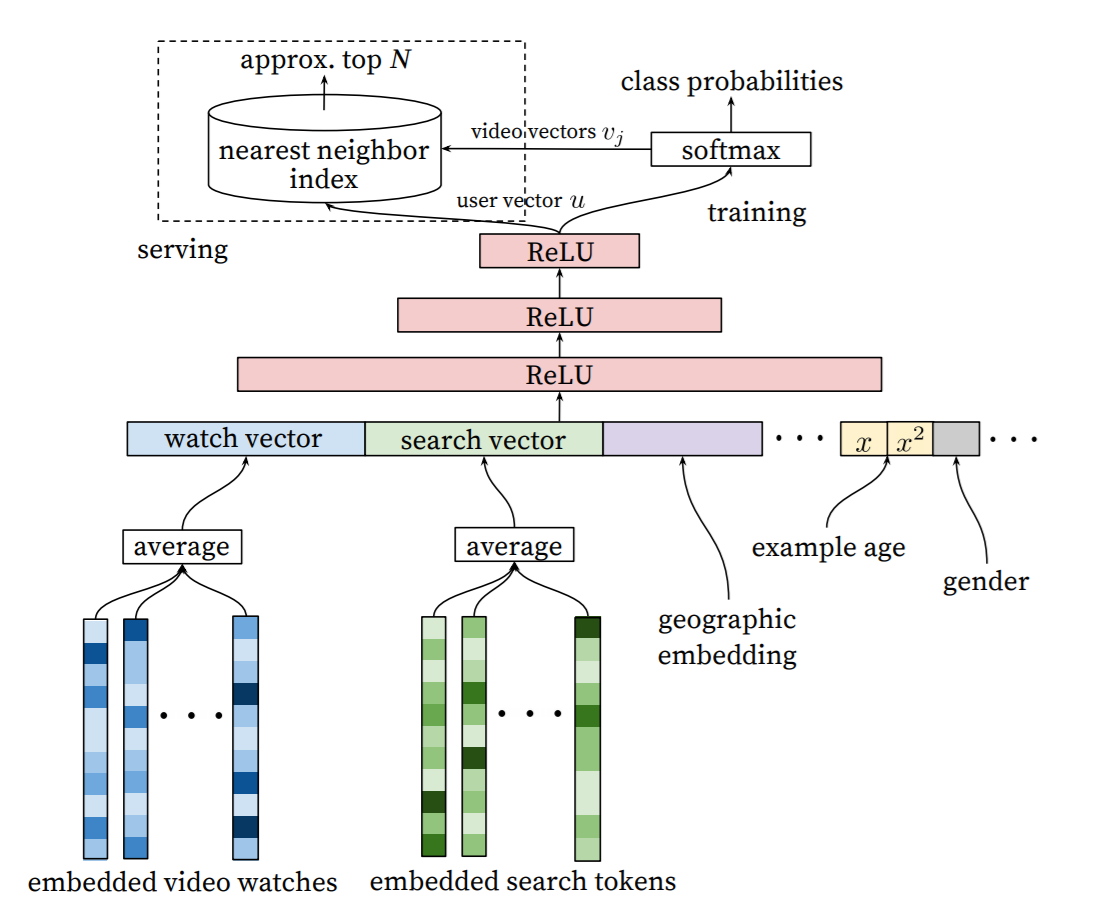
맨 아래 입력부터 맨 위 아웃풋까지 모델의 전체적인 구조인 그림이다. 이 그림에서 시청기록에 대한 부분(왼쪽 하단 파란색)을 자세하게 살펴보자.
시청기록을 고정된 길이의 고차원 임베딩 벡터로 만들어, 학습시키는 방법을 사용하고자 한다. (언어모델의 학습과 유사)
- 시청기록은 영상 ID에 대한 가변길이 시퀀스(sparse함)로 나타낼 수 있다. 이를 임베딩을 통해 dense vector representation(그림에서 embedded video watchs)으로 만든다.
- 모델은 고정길이 dense 입력이 필요하기 때문에, 임베딩 된 벡터를 평균낸다. 여러 방법을 시도해봤을 때, 평균이 가장 적합했다.
- 이를 다른 피처들과 함께 완전연결(fully connectec) ReLU 히든레이어에 넣는다.
이제 시청 기록 이외의 피처들을 살펴보자.
3.3 Heterogeneous Signals
- 검색 기록
- 시청 기록과 비슷한 방법으로 입력한다.
- 각 검색어를 unigram이나 bigram으로 토큰화하고, 이 토큰을 임베딩한다.
- 검색기록은 그림에서 초록색으로 표현되어 있다.
- 인구통계학적 피처
- 사용자의 위치, 기기정보는 임베딩하여 입력한다.
- 간단한 이진피처나 연속형 피처(성별, 로그인 상태, 나이)는 0과 1 사이의 값으로 표준화해서 값으로 입력한다.
“Example Age” Feature
- Youtube 입장에서 새로 업로드(fresh) 된 영상을 추천하는 것이 중요하다. 따라서 사용자가 새로운 컨텐츠를 좋아하는지 지속적으로 관찰한다.
- 하지만 머신러닝은 과거를 학습시켜 미래를 예측하기 때문에, 과거 기록에 대한 편향이 존재할 수 밖에 없다.
- 이를 해결하기 위해, 영상이 업로드 된 후의 시간(Example Age)을 입력으로 넣는다.

- baseline모델(파란색)은 학습기간(training window)내의 평균 가능성으로만 예측하지만,
- 업로드 된 후의 시간을 넣게 되면, 업로드 된 직후에 시청을 하는 경향을 잡아낼 수 있다.
3.4 Label and Context Selection
- 훈련예제는 모든 YouTube 시청 데이터로 생성
- 사용자가 추천 이외의 방법으로 영상을 찾을 때, 이 결과를 빠르게 전달한다.
- 사용자 별로 고정된 수의 훈련예제를 생성
- loss function에 모든 사용자들이 동일한 가중치를 가져가도록 한다.
- 이는 매우 활발한 소수의 사용자에게 집중되어 추천시스템이 만들어지는 것을 방지한다.
3.5 Experiments with Features and Depth
- 영상 100만개, 검색 토큰 100만개를 256차원으로 임베딩한다.
- 50개의 최근 시청기록과 50개의 최근 검색기록이 포함된다.
- 이 모델은 모든 사용자에 대해 수렴할 때까지 학습된다.
- 네트워크 구조는 아래 네트워크가 가장 넓고, 다음 은닉층으로 갈 때마다 절반으로 줄어드는 일반적인 탑 형태이다.
4. RANKING
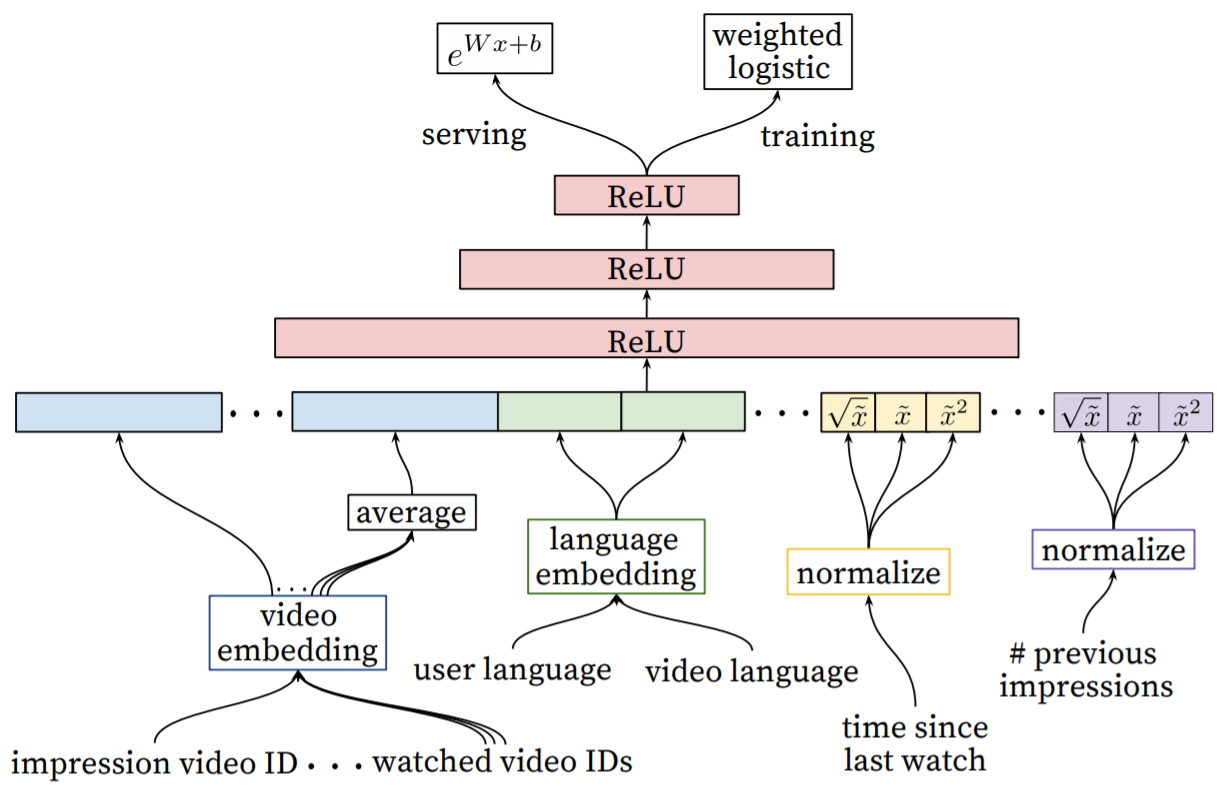
- 후보생성모델에서 영상의 범위를 많이 줄였기 때문에, 랭킹모델에서는 더 많은 피처를 살펴본다.
- 랭킹모델의 신경망 구조는 후보생성모델과 비슷하다. 로지스틱 회귀를 사용하여 각 영상 노출에 대한 독립적인 스코어를 만든다. 이 스코어로 영상에 순위를 매기고 사용자에게 추천해준다.
- 이 모델은 A/B 테스트를 통해서 실시간으로 튜닝되는데, 이때 평가기준은 추천횟수 대비 시청시간이다.
4.1 Feature Representation
데이터를 두가지 관점으로 나누고 있다.
- 데이터 형태에 따른 분류
- Continuous/Ordinal features
- Categorical features
- univalent : 하나의 값만을 갖는 피처 (ex.스코어링된 영상의 id)
- multivalent : 여러 값을 갖는 피처 (ex.지금까지 봤던 영상의 id)
- 데이터 의미에 따른 분류
- Impression features
- Query features
Feature Engineering
- 랭킹 모델에는 수백개의 피처를 사용한다. 딥러닝이 feature engineering을 줄여준다고 생각하지만, 이 논문에서는 상당한 엔지니어링 자원을 사용하고 있다.
- 랭킹모델에서 중요한 피처
- 영상에 대한 사용자의 과거 행동
- e.g. 사용자가 이 채널에서 얼마나 많은 영상을 시청했었는지 / 이 주제에 대한 영상을 마지막으로 본 시점이 언제였는지
- 후보생성모델에서 알게된 정보
- e.g. 후보영상을 선정한 소스가 무엇인지 / 후보생성모델에서의 점수가 몇 점이었는지
- 이전 추천 정보
- e.g. 이 영상이 이전까지 몇번이나 노출됐는지: 추천을 했는데 보지 않은 영상은 다음에 추천되지 않음(새로고침을 누르면 다른 영상이 나오는 이유)
- 영상에 대한 사용자의 과거 행동
Embedding Categorical Features
- 범주형 피처를 다루는 과정은 후보생성모델과 비슷하다.
- 임베딩으로 sparse categorical features를 dense representaions로 변환한다.
- oov 값들은 0으로 임베딩된다.
- 여러 값을 가질 수 있는(multivalent) 범주형 피처 임베딩은 평균내어 입력한다.
- 공유된 임베딩에도 불구하고, 피처들은 각각 입력된다. 따라서 이후 레이어에서는 각 피처마다 specialized representation으로 학습된다.
Normalizing Continuous Features
- 신경망은 스케일링에 매우 민감하다. 반면에 의사결정나무의 앙상블 같은 경우는 피처의 스케일에 영향을 받지 않는다.
- 이 논문의 모델에서는 연속형 피처에 알맞은 정규화를 하는 것이 수렴하는데 매우 중요하다.
4.2 Modeling Expected Watch Time
- 목표는 주어진 트레이닝 데이터로 시청 시간을 예측하는 것이다. 트레이닝 데이터는 positive(추천된 영상을 클릭함)인/negative(추천된 영상을 클릭하지 않음) 상관이 없다. positive 데이터에는 사용자가 영상을 시청하는데 얼마나 시간을 썼는지도 나타나 있다.
- wighted logistic regression을 사용한다. cross-entropy loss를 줄이는 방향으로 학습힌다.
- 클릭된(positive) 추천 영상은 시청시간에 따라 가중치가 반영된다.
- 클릭되지 않은(negative) 추천 영상은 unit 가중치를 반영한다.
- 지수함수를 마지막 활성함수로 사용한다.
4.3 Experiments with Hidden Layers

- 각 구조(weighted, per-user loss)는 하나의 페이지에서 클릭된(positive)영상과 클릭되지 않은(negative) 영상을 모두 고려했다.
- 두 종류의 영상에 모두 점수를 매긴다. 클릭되지 않은 영상이 클릭된 영상보다 더 높은 점수를 받게 되면, 클릭된 영상의 시청시간을 잘못 예측된(mispredicted) 시청시간으로 고려한다.
- 따라서 weighted, per-user loss는 잘못 예측된 시청시간의 합이 된다.
- 최종 구조 : 1024 ReLU -> 512 ReLu -> 256 ReLU
- 표준화만 한 범주형 변수 사용한다. power->loss 0.2% 증가
- positive/negative 데이터에 동일하게 가중치를 주면 loss가 4.1%로 급격하게 늘어남
5. CONCLUSIONS
YouTube 동영상 추천을 위한 심층신경망 구조를 두가지로 나눠서 구현했다 : 후보생성과 랭킹. feature engineering이 많은 부분을 차지하고 있고, YouTube의 비즈니스 인사이트를 기반으로 만든 피처들이 중요하게 작용했다.
Leave a comment